 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Precision Reinforcement Learning
Paper and Code
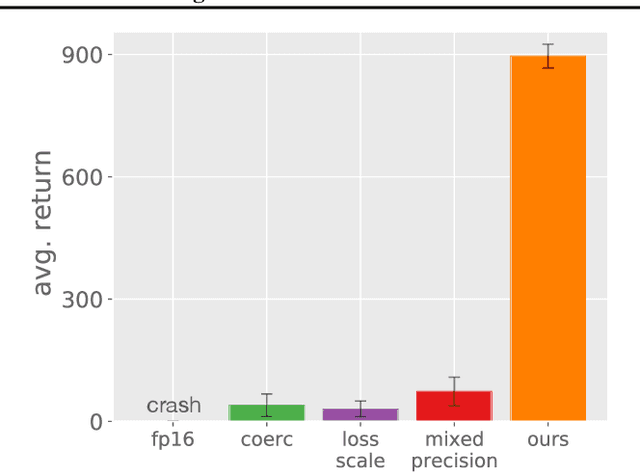

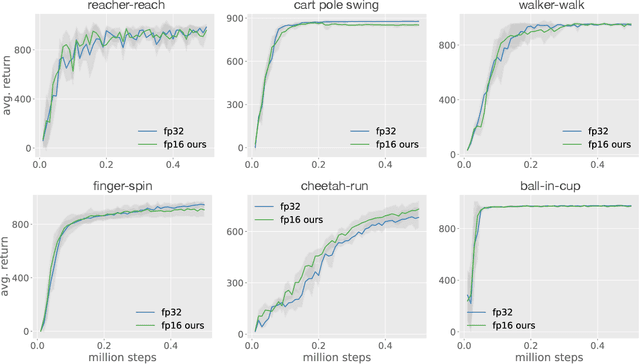
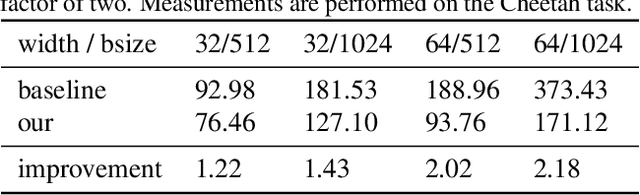
Low-precision training has become a popular approach to reduce computation time, memory footprint, and energy consumption in supervised learning. In contrast, this promising approach has not enjoyed similarly widespread adoption within the reinforcement learning (RL) community, in part because RL agents can be notoriously hard to train -- even in full precision. In this paper we consider continuous control with the state-of-the-art SAC agent and demonstrate that a na\"ive adaptation of low-precision methods from supervised learning fails. We propose a set of six modifications, all straightforward to implement, that leaves the underlying agent unchanged but improves its numerical stability dramatically. The resulting modified SAC agent has lower memory and compute requirements while matching full-precision rewards, thus demonstrating the feasibility of low-precision RL.