 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Factor Adaptation for User Embedding via Multitask Learning
Paper and Code

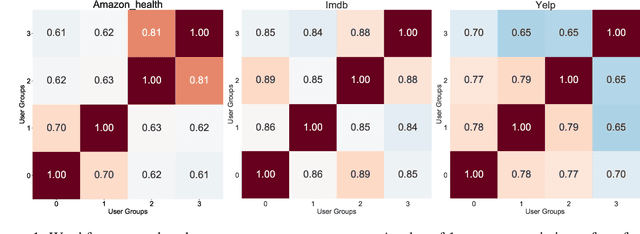
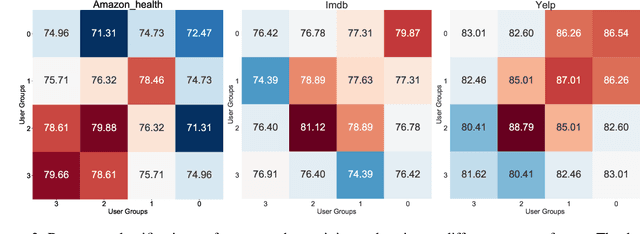
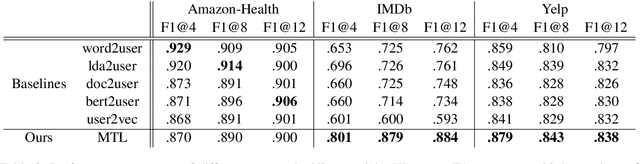
Language varies across users and their interested fields in social media data: words authored by a user across his/her interests may have different meanings (e.g., cool) or sentiments (e.g., fast). However, most of the existing methods to train user embeddings ignore the variations across user interests, such as product and movie categories (e.g., drama vs. action). In this study, we treat the user interest as domains and empirically examine how the user language can vary across the user factor in three English social media datasets. We then propose a user embedding model to account for the language variability of user interests via a multitask learning framework. The model learns user language and its variations without human supervision. While existing work mainly evaluated the user embedding by extrinsic tasks, we propose an intrinsic evaluation via clustering and evaluate user embeddings by an extrinsic task, text classification. The experiments on the three English-language social media datasets show that our proposed approach can generally outperform baselines via adapting the user factor.