 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualGPT: Data-efficient Image Captioning by Balancing Visual Input and Linguistic Knowledge from Pretraining
Paper and Code
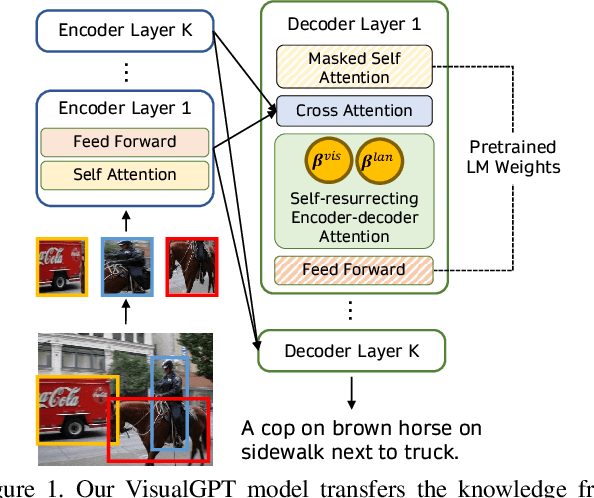
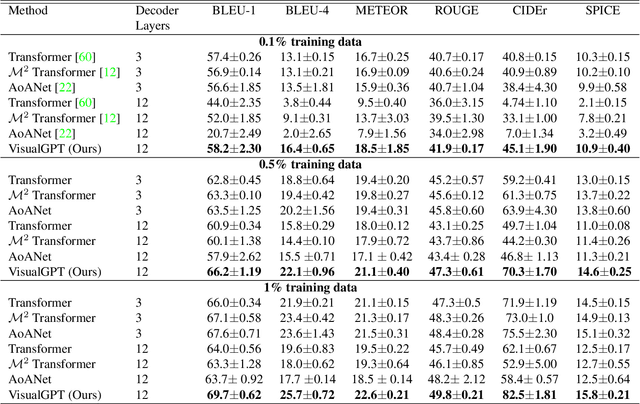
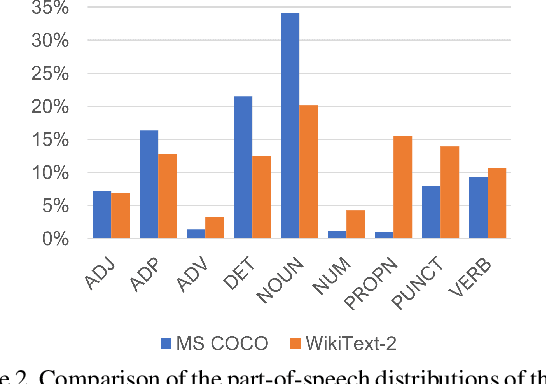
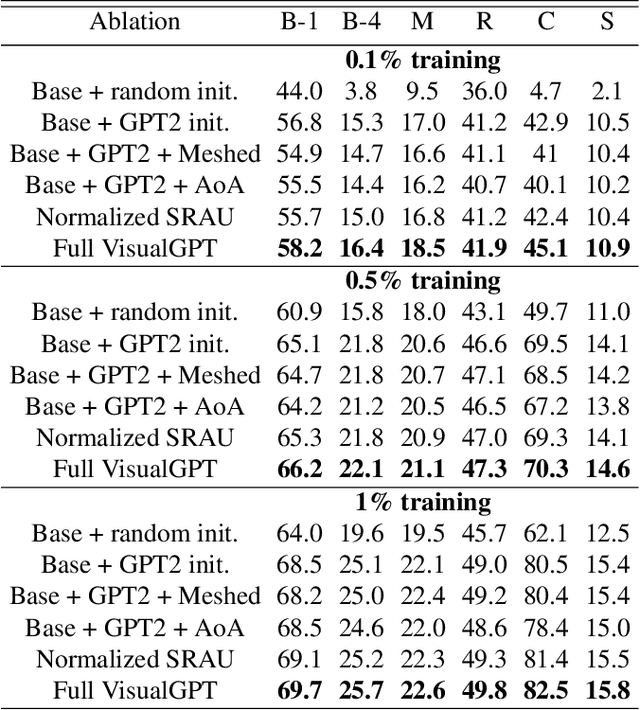
In this paper, we aim to improve the data efficiency of image captioning. We propose VisualGPT, a data-efficient image captioning model that leverages the linguistic knowledge from a large pretrained language model (LM). A crucial challenge is to balance between the use of visual information in the image and prior linguistic knowledge acquired from pretraining.We designed a novel self-resurrecting encoder-decoder attention mechanism to quickly adapt the pretrained LM as the language decoder on a small amount of in-domain training data. The pro-posed self-resurrecting activation unit produces sparse activations but is not susceptible to zero gradients. When trained on 0.1%, 0.5% and 1% of MSCOCO and Conceptual Captions, the proposed model, VisualGPT, surpasses strong image captioning baselines. VisualGPT outperforms the best baseline model by up to 10.8% CIDEr on MS COCO and up to 5.4% CIDEr on Conceptual Captions.We also perform a series of ablation studies to quantify the utility of each system component. To the best of our knowledge, this is the first work that improves data efficiency of image captioning by utilizing LM pretrained on unimodal data. Our code is available at: https://github.com/Vision-CAIR/VisualGPT.