 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Co-design of Neural Architectures and Hardware Accelerators
Paper and Code
Feb 17, 2021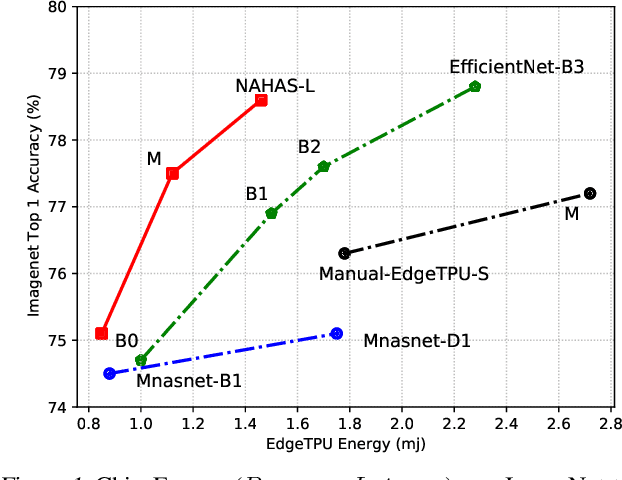
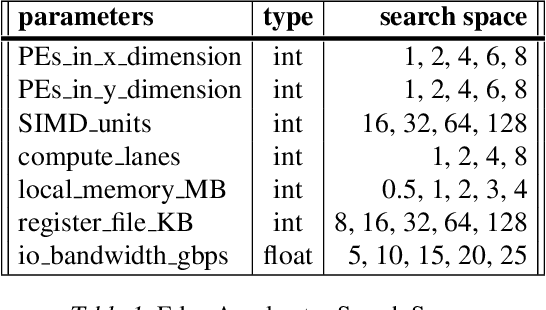
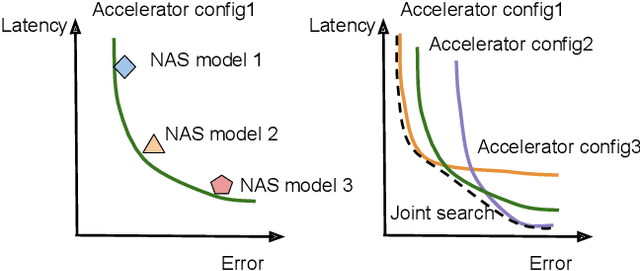
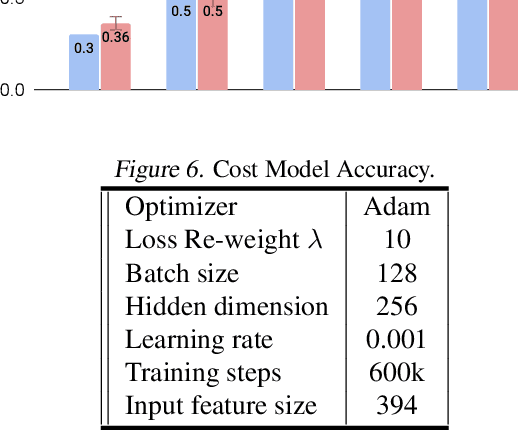
Neural architectures and hardware accelerators have been two driving forces for the progress in deep learning. Previous works typically attempt to optimize hardware given a fixed model architecture or model architecture given fixed hardware. And the dominant hardware architecture explored in this prior work is FPGAs. In our work, we target the optimization of hardware and software configurations on an industry-standard edge accelerator. We systematically study the importance and strategies of co-designing neural architectures and hardware accelerators. We make three observations: 1) the software search space has to be customized to fully leverage the targeted hardware architecture, 2) the search for the model architecture and hardware architecture should be done jointly to achieve the best of both worlds, and 3) different use cases lead to very different search outcomes. Our experiments show that the joint search method consistently outperforms previous platform-aware neural architecture search, manually crafted models, and the state-of-the-art EfficientNet on all latency targets by around 1% on ImageNet top-1 accuracy. Our method can reduce energy consumption of an edge accelerator by up to 2x under the same accuracy constraint, when co-adapting the model architecture and hardware accelerator configurations.