 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATE: Computation-aware Neural Architecture Encoding with Transformers
Paper and Code
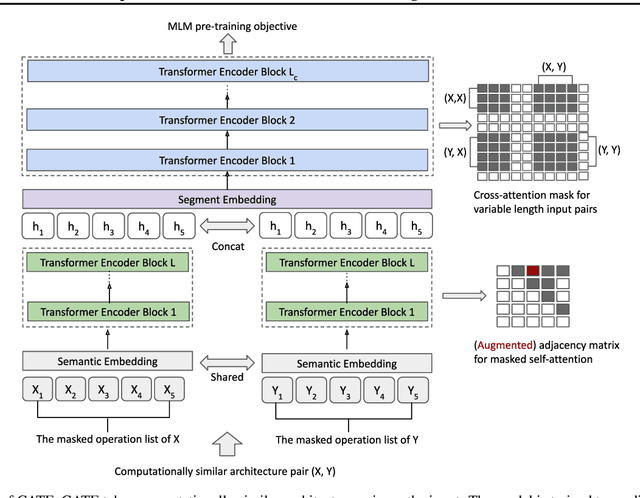
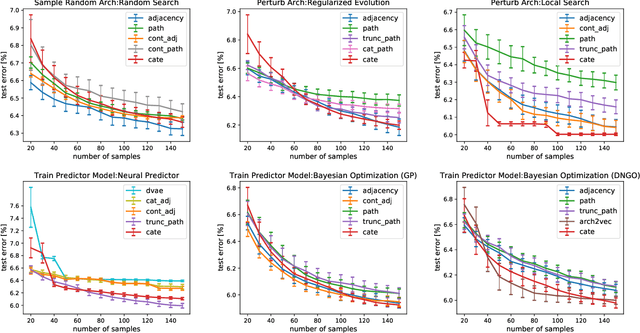
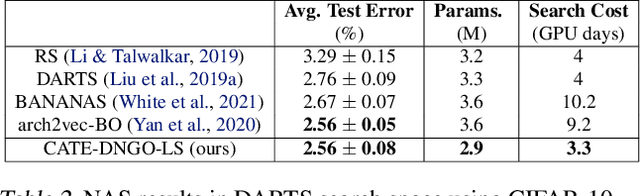
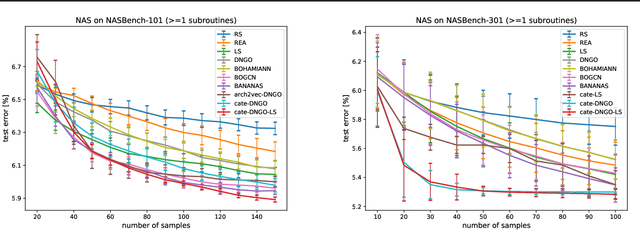
Recent works (White et al., 2020a; Yan et al., 2020) demonstrate the importance of architecture encodings in Neural Architecture Search (NAS). These encodings encode either structure or computation information of the neural architectures. Compared to structure-aware encodings, computation-aware encodings map architectures with similar accuracies to the same region, which improves the downstream architecture search performance (Zhang et al., 2019; White et al., 2020a). In this work, we introduce a Computation-Aware Transformer-based Encoding method called CATE. Different from existing computation-aware encodings based on fixed transformation (e.g. path encoding), CATE employs a pairwise pre-training scheme to learn computation-aware encodings using Transformers with cross-attention. Such learned encodings contain dense and contextualized computation information of neural architectures. We compare CATE with eleven encodings under three major encoding-dependent NAS subroutines in both small and large search spaces. Our experiments show that CATE is beneficial to the downstream search, especially in the large search space. Moreover, the outside search space experiment shows its superior generalization ability beyond the search space on which it was trained.