 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashion Focus: Multi-modal Retrieval System for Video Commodity Localization in E-commerce
Paper and Code
Feb 09, 2021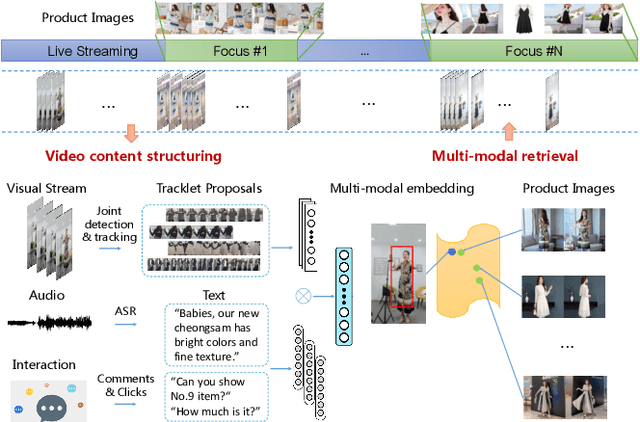

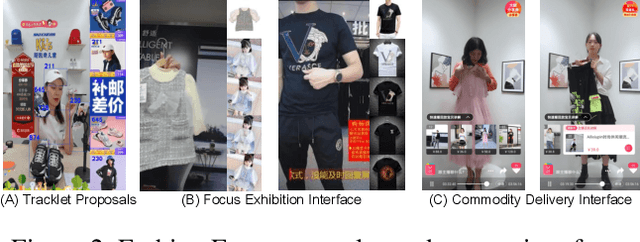
Nowadays, live-stream and short video shopping in E-commerce have grown exponentially. However, the sellers are required to manually match images of the selling products to the timestamp of exhibition in the untrimmed video, resulting in a complicated process. To solve the problem, we present an innovative demonstration of multi-modal retrieval system called "Fashion Focus", which enables to exactly localize the product images in the online video as the focuses. Different modality contributes to the community localization, including visual content, linguistic features and interaction context are jointly investigated via presented multi-modal learning. Our system employs two procedures for analysis, including video content structuring and multi-modal retrieval, to automatically achieve accurate video-to-shop matching. Fashion Focus presents a unified framework that can orientate the consumers towards relevant product exhibitions during watching videos and help the sellers to effectively deliver the products over search and recommendation.