 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private SGD with Non-Smooth Loss
Paper and Code
Jan 22, 2021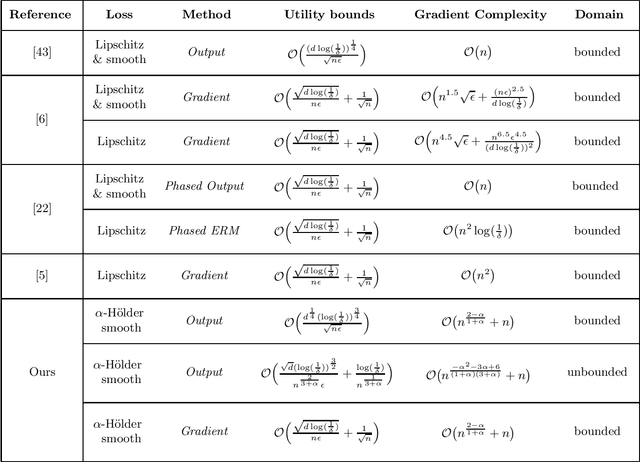
In this paper, we are concerned with differentially private SGD algorithms in the setting of stochastic convex optimization (SCO). Most of existing work requires the loss to be Lipschitz continuous and strongly smooth, and the model parameter to be uniformly bounded. However, these assumptions are restrictive as many popular losses violate these conditions including the hinge loss for SVM, the absolute loss in robust regression, and even the least square loss in an unbounded domain. We significantly relax these restrictive assumptions and establish privacy and generalization (utility) guarantees for private SGD algorithms using output and gradient perturbations associated with non-smooth convex losses. Specifically, the loss function is relaxed to have $\alpha$-H\"{o}lder continuous gradient (referred to as $\alpha$-H\"{o}lder smoothness) which instantiates the Lipschitz continuity ($\alpha=0$) and strong smoothness ($\alpha=1$). We prove that noisy SGD with $\alpha$-H\"older smooth losses using gradient perturbation can guarantee $(\epsilon,\delta)$-differential privacy (DP) and attain optimal excess population risk $O\Big(\frac{\sqrt{d\log(1/\delta)}}{n\epsilon}+\frac{1}{\sqrt{n}}\Big)$, up to logarithmic terms, with gradient complexity (i.e. the total number of iterations) $T =O( n^{2-\alpha\over 1+\alpha}+ n).$ This shows an important trade-off between $\alpha$-H\"older smoothness of the loss and the computational complexity $T$ for private SGD with statistically optimal performance. In particular, our results indicate that $\alpha$-H\"older smoothness with $\alpha\ge {1/2}$ is sufficient to guarantee $(\epsilon,\delta)$-DP of noisy SGD algorithms while achieving optimal excess risk with linear gradient complexity $T = O(n).$