Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast convolutional neural networks on FPGAs with hls4ml
Paper and Code
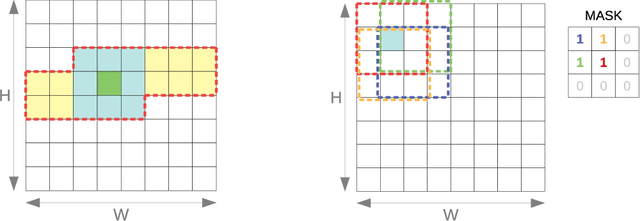
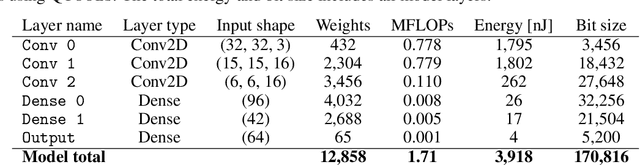
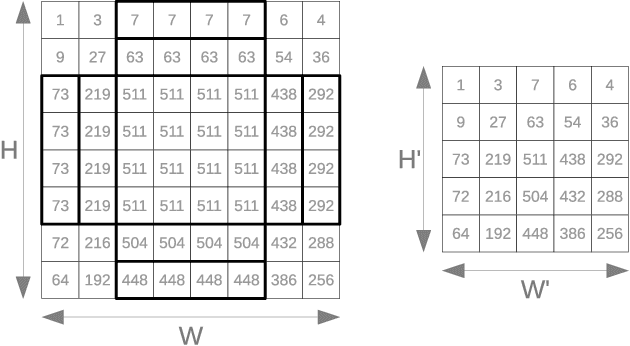

We introduce an automated tool for deploying ultra low-latency, low-power deep neural networks with large convolutional layers on FPGAs. By extending the hls4ml library, we demonstrate how to achieve inference latency of $5\,\mu$s using convolutional architectures, while preserving state-of-the-art model performance. Considering benchmark models trained on the Street View House Numbers Dataset, we demonstrate various methods for model compression in order to fit the computational constraints of a typical FPGA device. In particular, we discuss pruning and quantization-aware training, and demonstrate how resource utilization can be reduced by over 90% while maintaining the original model accuracy.
* 18 pages, 16 figures, 3 tables
View paper on