 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtecting Big Data Privacy Using Randomized Tensor Network Decomposition and Dispersed Tensor Computation
Paper and Code
Jan 04, 2021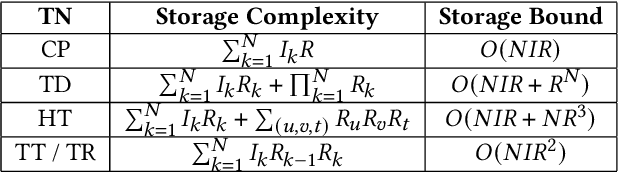
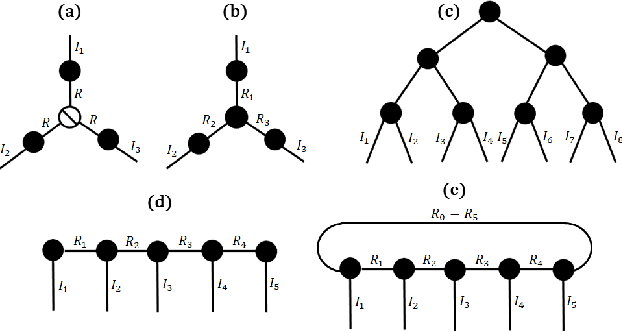
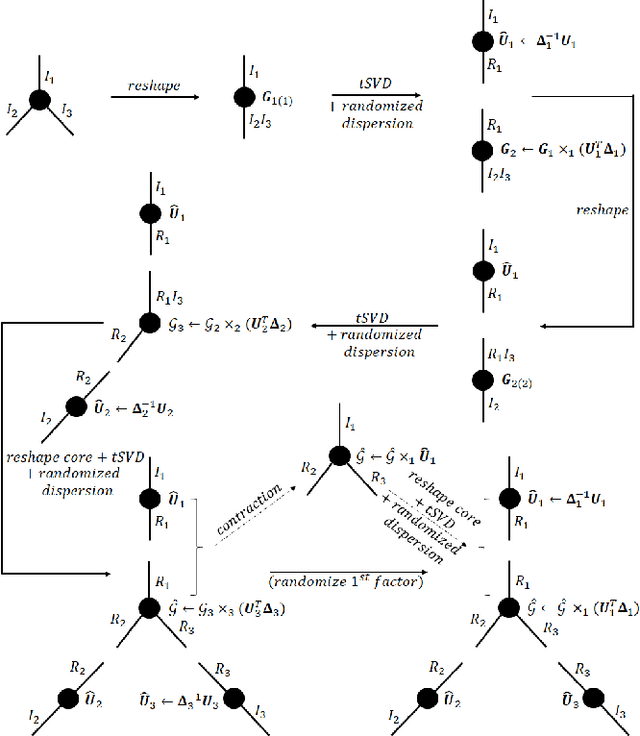
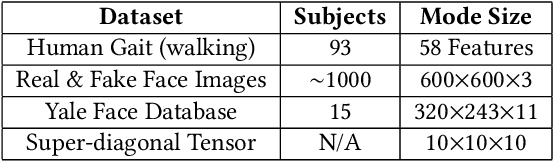
Data privacy is an important issue for organizations and enterprises to securely outsource data storage, sharing, and computation on clouds / fogs. However, data encryption is complicated in terms of the key management and distribution; existing secure computation techniques are expensive in terms of computational / communication cost and therefore do not scale to big data computation. Tensor network decomposition and distributed tensor computation have been widely used in signal processing and machine learning for dimensionality reduction and large-scale optimization. However, the potential of distributed tensor networks for big data privacy preservation have not been considered before, this motivates the current study. Our primary intuition is that tensor network representations are mathematically non-unique, unlinkable, and uninterpretable; tensor network representations naturally support a range of multilinear operations for compressed and distributed / dispersed computation. Therefore, we propose randomized algorithms to decompose big data into randomized tensor network representations and analyze the privacy leakage for 1D to 3D data tensors. The randomness mainly comes from the complex structural information commonly found in big data; randomization is based on controlled perturbation applied to the tensor blocks prior to decomposition. The distributed tensor representations are dispersed on multiple clouds / fogs or servers / devices with metadata privacy, this provides both distributed trust and management to seamlessly secure big data storage, communication, sharing, and computation. Experiments show that the proposed randomization techniques are helpful for big data anonymization and efficient for big data storage and computation.