 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDA: Improving Text Generation with Self Data Augmentation
Paper and Code
Jan 02, 2021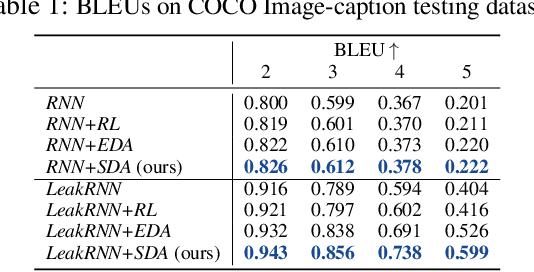
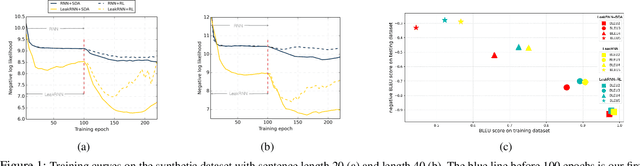
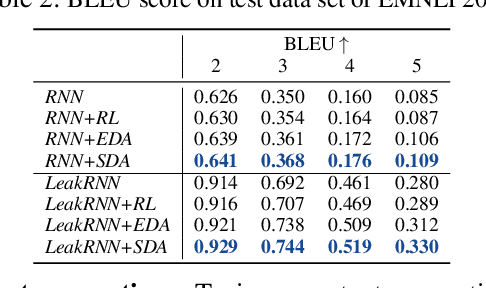

Data augmentation has been widely used to improve deep neural networks in many research fields, such as computer vision. However, less work has been done in the context of text, partially due to its discrete nature and the complexity of natural languages. In this paper, we propose to improve the standard maximum likelihood estimation (MLE) paradigm by incorporating a self-imitation-learning phase for automatic data augmentation. Unlike most existing sentence-level augmentation strategies, which are only applied to specific models, our method is more general and could be easily adapted to any MLE-based training procedure. In addition, our framework allows task-specific evaluation metrics to be designed to flexibly control the generated sentences, for example, in terms of controlling vocabulary usage and avoiding nontrivial repetitions. Extensive experimental results demonstrate the superiority of our method on two synthetic and several standard real datasets, significantly improving related baselines.