 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphHop: An Enhanced Label Propagation Method for Node Classification
Paper and Code
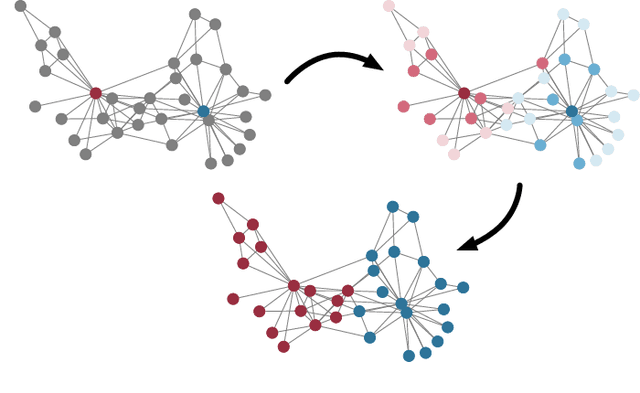
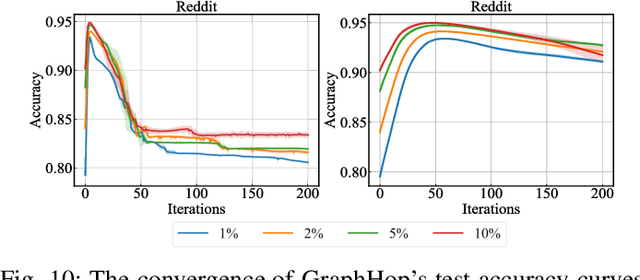
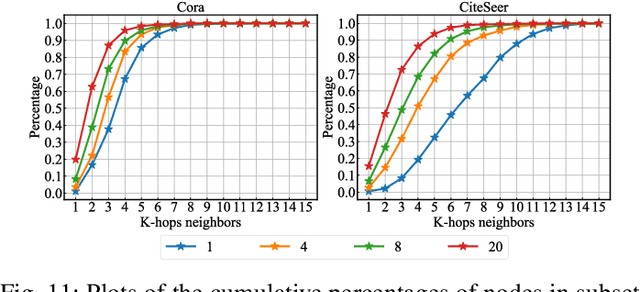
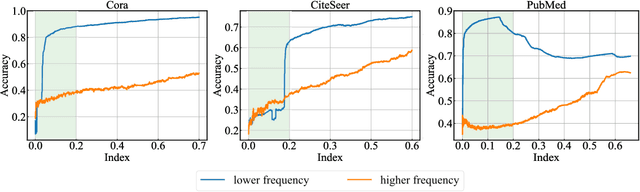
A scalable semi-supervised node classification method on graph-structured data, called GraphHop, is proposed in this work. The graph contains attributes of all nodes but labels of a few nodes. The classical label propagation (LP) method and the emerging graph convolutional network (GCN) are two popular semi-supervised solutions to this problem. The LP method is not effective in modeling node attributes and labels jointly or facing a slow convergence rate on large-scale graphs. GraphHop is proposed to its shortcoming. With proper initial label vector embeddings, each iteration of GraphHop contains two steps: 1) label aggregation and 2) label update. In Step 1, each node aggregates its neighbors' label vectors obtained in the previous iteration. In Step 2, a new label vector is predicted for each node based on the label of the node itself and the aggregated label information obtained in Step 1. This iterative procedure exploits the neighborhood information and enables GraphHop to perform well in an extremely small label rate setting and scale well for very large graphs. Experimental results show that GraphHop outperforms state-of-the-art graph learning methods on a wide range of tasks (e.g., multi-label and multi-class classification on citation networks, social graphs, and commodity consumption graphs) in graphs of various sizes. Our codes are publicly available on GitHub (https://github.com/TianXieUSC/GraphHop).