 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypothesis Stitcher for End-to-End Speaker-attributed ASR on Long-form Multi-talker Recordings
Paper and Code
Jan 06, 2021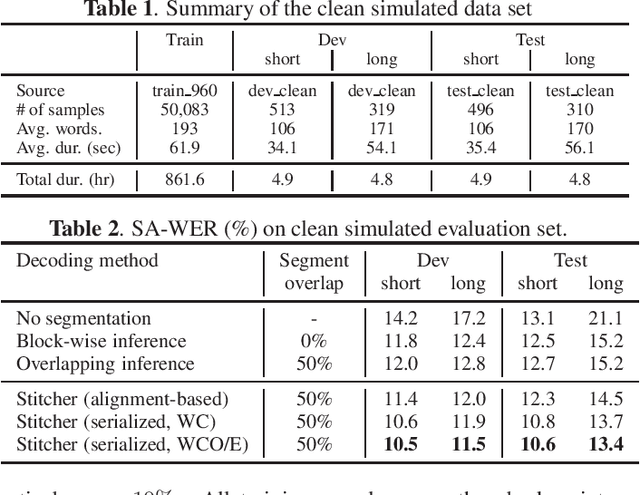
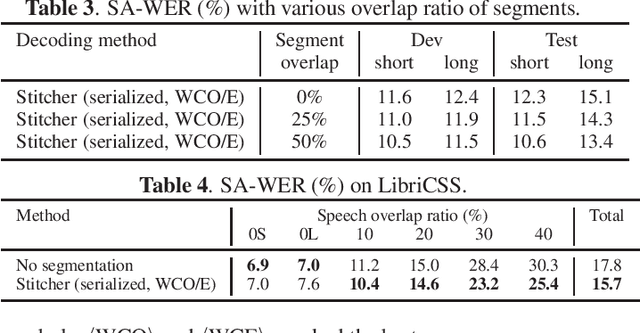
An end-to-end (E2E) speaker-attributed automatic speech recognition (SA-ASR) model was proposed recently to jointly perform speaker counting, speech recognition and speaker identification. The model achieved a low speaker-attributed word error rate (SA-WER) for monaural overlapped speech comprising an unknown number of speakers. However, the E2E modeling approach is susceptible to the mismatch between the training and testing conditions. It has yet to be investigated whether the E2E SA-ASR model works well for recordings that are much longer than samples seen during training. In this work, we first apply a known decoding technique that was developed to perform single-speaker ASR for long-form audio to our E2E SA-ASR task. Then, we propose a novel method using a sequence-to-sequence model, called hypothesis stitcher. The model takes multiple hypotheses obtained from short audio segments that are extracted from the original long-form input, and it then outputs a fused single hypothesis. We propose several architectural variations of the hypothesis stitcher model and compare them with the conventional decoding methods. Experiments using LibriSpeech and LibriCSS corpora show that the proposed method significantly improves SA-WER especially for long-form multi-talker recordings.