 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Mandarin TTS Front-end Based on Distilled BERT Model
Paper and Code

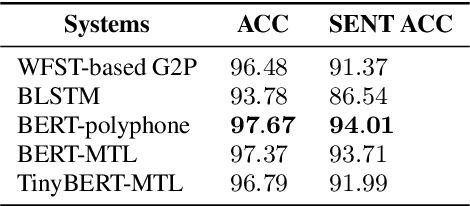
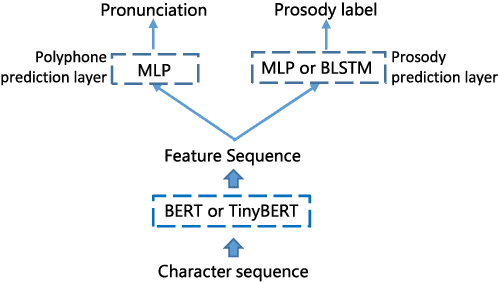
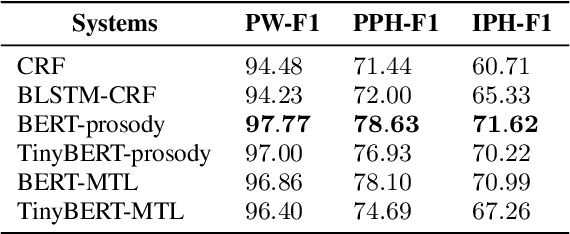
The front-end module in a typical Mandarin text-to-speech system (TTS) is composed of a long pipeline of text processing components, which requires extensive efforts to build and is prone to large accumulative model size and cascade errors. In this paper, a pre-trained language model (PLM) based model is proposed to simultaneously tackle the two most important tasks in TTS front-end, i.e., prosodic structure prediction (PSP) and grapheme-to-phoneme (G2P) conversion. We use a pre-trained Chinese BERT[1] as the text encoder and employ multi-task learning technique to adapt it to the two TTS front-end tasks. Then, the BERT encoder is distilled into a smaller model by employing a knowledge distillation technique called TinyBERT[2], making the whole model size 25% of that of benchmark pipeline models while maintaining competitive performance on both tasks. With the proposed the methods, we are able to run the whole TTS front-end module in a light and unified manner, which is more friendly to deployment on mobile devices.