 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenViDial: A Large-Scale, Open-Domain Dialogue Dataset with Visual Contexts
Paper and Code



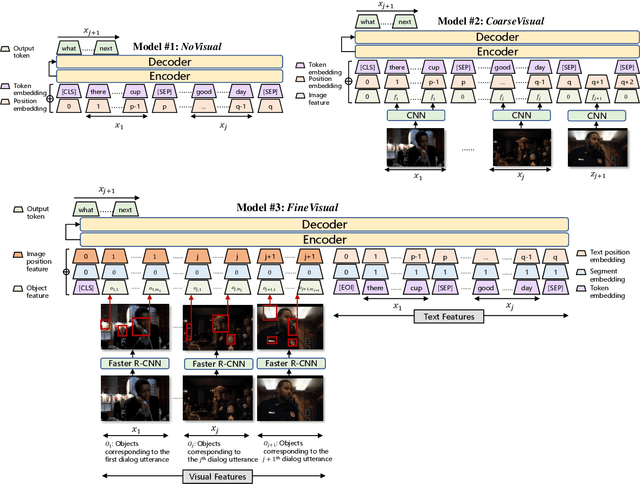
When humans converse, what a speaker will say next significantly depends on what he sees. Unfortunately, existing dialogue models generate dialogue utterances only based on preceding textual contexts, and visual contexts are rarely considered. This is due to a lack of a large-scale multi-module dialogue dataset with utterances paired with visual contexts. In this paper, we release {\bf OpenViDial}, a large-scale multi-module dialogue dataset. The dialogue turns and visual contexts are extracted from movies and TV series, where each dialogue turn is paired with the corresponding visual context in which it takes place. OpenViDial contains a total number of 1.1 million dialogue turns, and thus 1.1 million visual contexts stored in images. Based on this dataset, we propose a family of encoder-decoder models leveraging both textual and visual contexts, from coarse-grained image features extracted from CNNs to fine-grained object features extracted from Faster R-CNNs. We observe that visual information significantly improves dialogue generation qualities, verifying the necessity of integrating multi-modal features for dialogue learning. Our work marks an important step towards large-scale multi-modal dialogue learning.