 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree Ways to Improve Semantic Segmentation with Self-Supervised Depth Estimation
Paper and Code
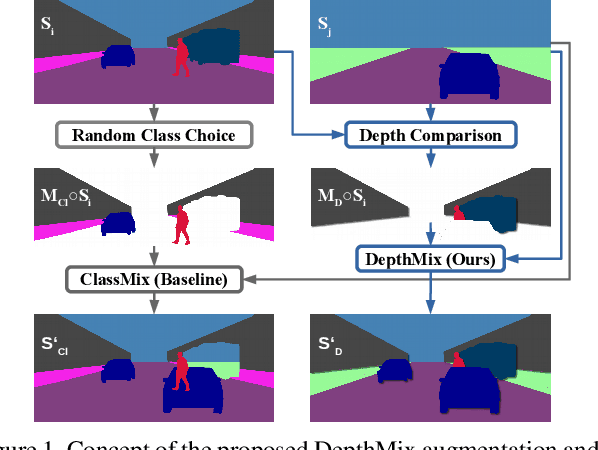
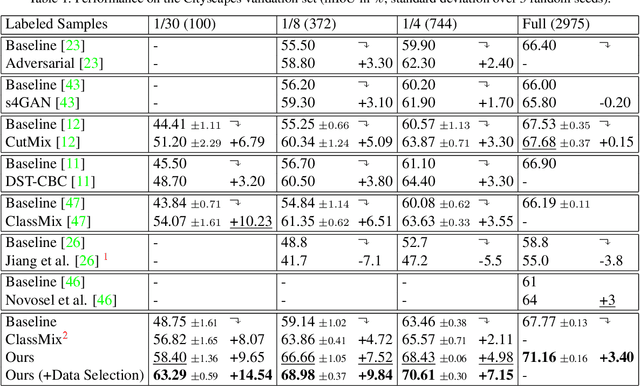
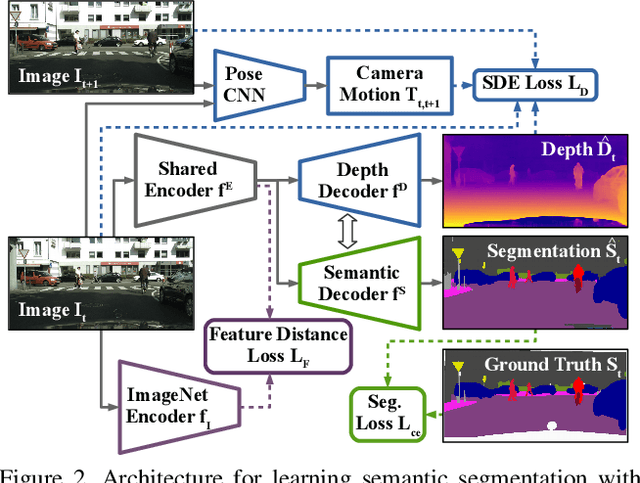
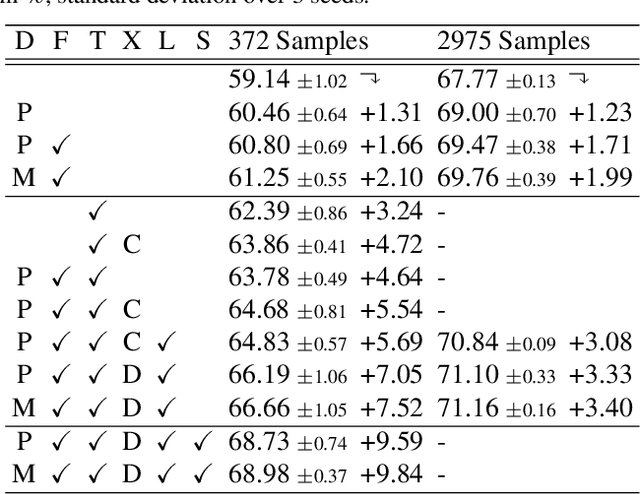
Training deep networks for semantic segmentation requires large amounts of labeled training data, which presents a major challenge in practice, as labeling segmentation masks is a highly labor-intensive process. To address this issue, we present a framework for semi-supervised semantic segmentation, which is enhanced by self-supervised monocular depth estimation from unlabeled images. In particular, we propose three key contributions: (1) We transfer knowledge from features learned during self-supervised depth estimation to semantic segmentation, (2) we implement a strong data augmentation by blending images and labels using the structure of the scene, and (3) we utilize the depth feature diversity as well as the level of difficulty of learning depth in a student-teacher framework to select the most useful samples to be annotated for semantic segmentation. We validate the proposed model on the Cityscapes dataset, where all three modules demonstrate significant performance gains, and we achieve state-of-the-art results for semi-supervised semantic segmentation. The implementation is available at https://github.com/lhoyer/improving_segmentation_with_selfsupervised_depth.