 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA review of on-device fully neural end-to-end automatic speech recognition algorithms
Paper and Code
Dec 19, 2020
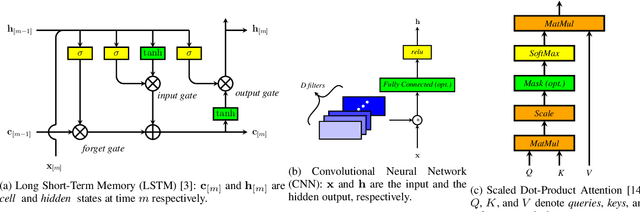
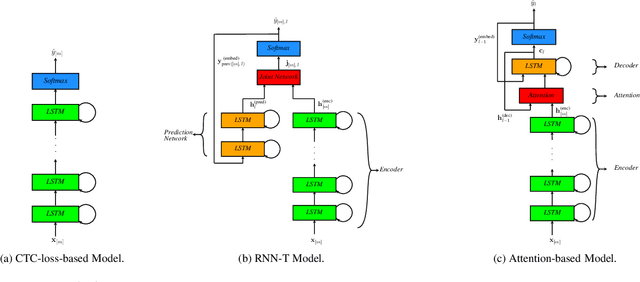
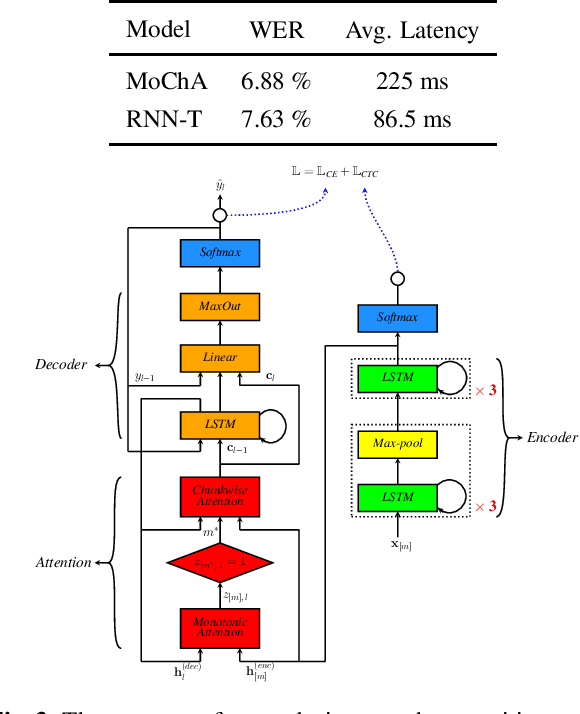
In this paper, we review various end-to-end automatic speech recognition algorithms and their optimization techniques for on-device applications. Conventional speech recognition systems comprise a large number of discrete components such as an acoustic model, a language model, a pronunciation model, a text-normalizer, an inverse-text normalizer, a decoder based on a Weighted Finite State Transducer (WFST), and so on. To obtain sufficiently high speech recognition accuracy with such conventional speech recognition systems, a very large language model (up to 100 GB) is usually needed. Hence, the corresponding WFST size becomes enormous, which prohibits their on-device implementation. Recently, fully neural network end-to-end speech recognition algorithms have been proposed. Examples include speech recognition systems based on Connectionist Temporal Classification (CTC), Recurrent Neural Network Transducer (RNN-T), Attention-based Encoder-Decoder models (AED), Monotonic Chunk-wise Attention (MoChA), transformer-based speech recognition systems, and so on. These fully neural network-based systems require much smaller memory footprints compared to conventional algorithms, therefore their on-device implementation has become feasible. In this paper, we review such end-to-end speech recognition models. We extensively discuss their structures, performance, and advantages compared to conventional algorithms.