 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised reward learning for offline reinforcement learning
Paper and Code
Dec 12, 2020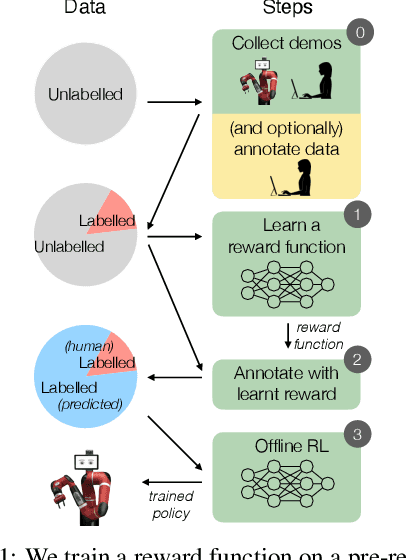
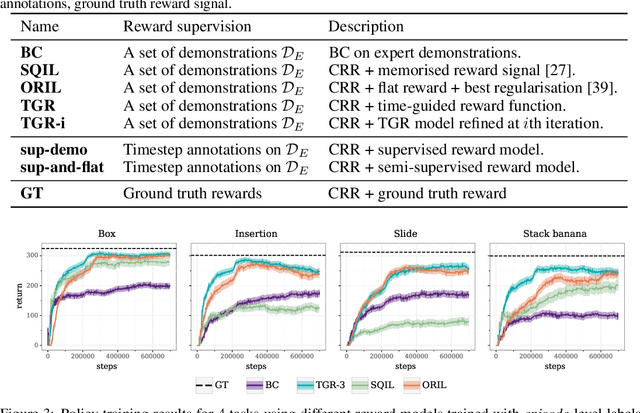

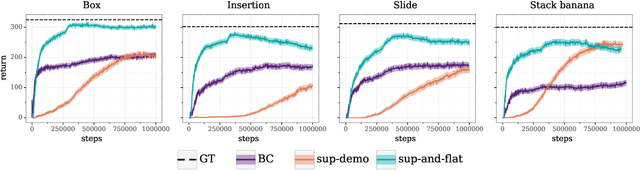
In offline reinforcement learning (RL) agents are trained using a logged dataset. It appears to be the most natural route to attack real-life applications because in domains such as healthcare and robotics interactions with the environment are either expensive or unethical. Training agents usually requires reward functions, but unfortunately, rewards are seldom available in practice and their engineering is challenging and laborious. To overcome this, we investigate reward learning under the constraint of minimizing human reward annotations. We consider two types of supervision: timestep annotations and demonstrations. We propose semi-supervised learning algorithms that learn from limited annotations and incorporate unlabelled data. In our experiments with a simulated robotic arm, we greatly improve upon behavioural cloning and closely approach the performance achieved with ground truth rewards. We further investigate the relationship between the quality of the reward model and the final policies. We notice, for example, that the reward models do not need to be perfect to result in useful policies.