 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMO-LTR: Multiple Object Localization, Tracking, and Reconstruction from Monocular RGB Videos
Paper and Code
Dec 09, 2020


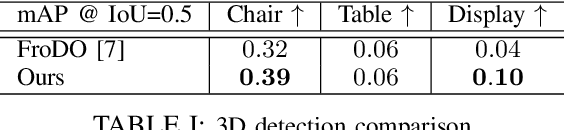
Semantic aware reconstruction is more advantageous than geometric-only reconstruction for future robotic and AR/VR applications because it represents not only where things are, but also what things are. Object-centric mapping is a task to build an object-level reconstruction where objects are separate and meaningful entities that convey both geometry and semantic information. In this paper, we present MO-LTR, a solution to object-centric mapping using only monocular image sequences and camera poses. It is able to localize, track, and reconstruct multiple objects in an online fashion when an RGB camera captures a video of the surrounding. Given a new RGB frame, MO-LTR firstly applies a monocular 3D detector to localize objects of interest and extract their shape codes that represent the object shape in a learned embedding space. Detections are then merged to existing objects in the map after data association. Motion state (i.e. kinematics and the motion status) of each object is tracked by a multiple model Bayesian filter and object shape is progressively refined by fusing multiple shape code. We evaluate localization, tracking, and reconstruction on benchmarking datasets for indoor and outdoor scenes, and show superior performance over previous approaches.