 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale 2D Temporal Adjacent Networks for Moment Localization with Natural Language
Paper and Code
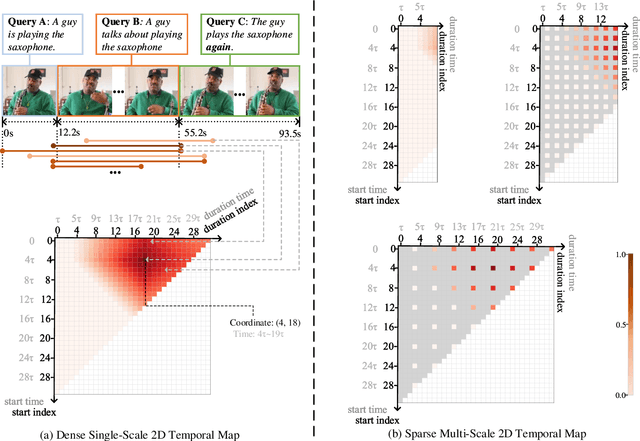
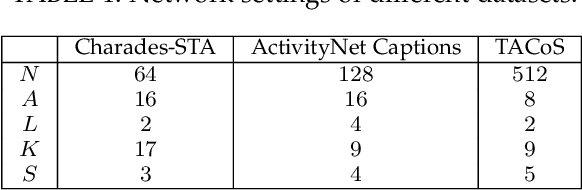
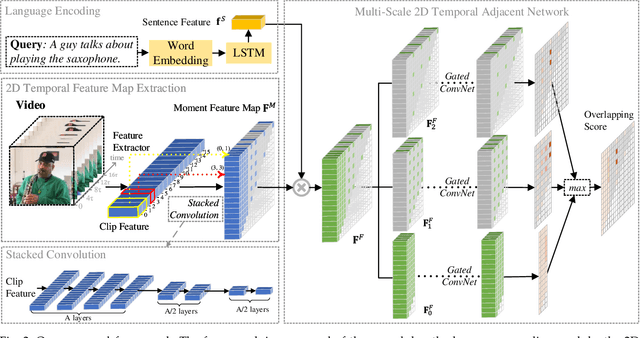
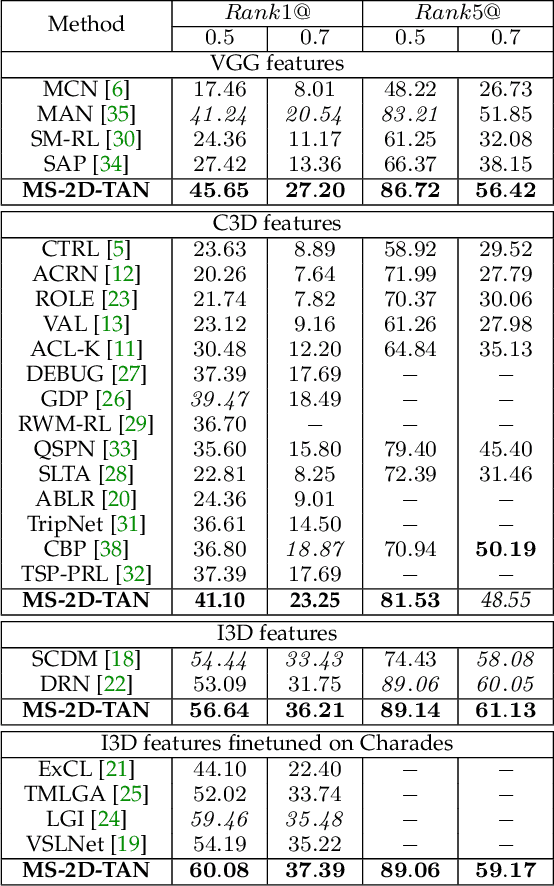
We address the problem of retrieving a specific moment from an untrimmed video by natural language. It is a challenging problem because a target moment may take place in the context of other temporal moments in the untrimmed video. Existing methods cannot tackle this challenge well since they do not fully consider the temporal contexts between temporal moments. In this paper, we model the temporal context between video moments by a set of predefined two-dimensional maps under different temporal scales. For each map, one dimension indicates the starting time of a moment and the other indicates the duration. These 2D temporal maps can cover diverse video moments with different lengths, while representing their adjacent contexts at different temporal scales. Based on the 2D temporal maps, we propose a Multi-Scale Temporal Adjacent Network (MS-2D-TAN), a single-shot framework for moment localization. It is capable of encoding the adjacent temporal contexts at each scale, while learning discriminative features for matching video moments with referring expressions. We evaluate the proposed MS-2D-TAN on three challenging benchmarks, i.e., Charades-STA, ActivityNet Captions, and TACoS, where our MS-2D-TAN outperforms the state of the art.