 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer Pruning via Fusible Residual Convolutional Block for Deep Neural Networks
Paper and Code
Nov 29, 2020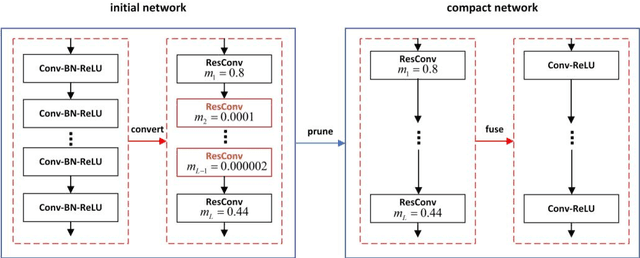
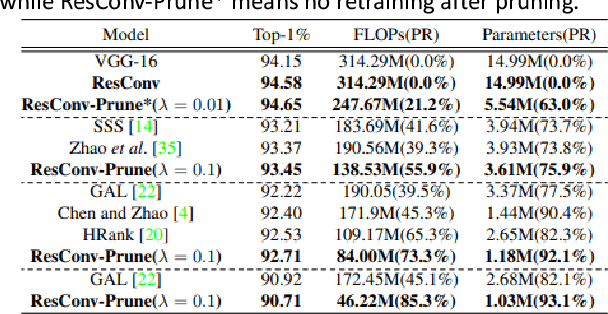
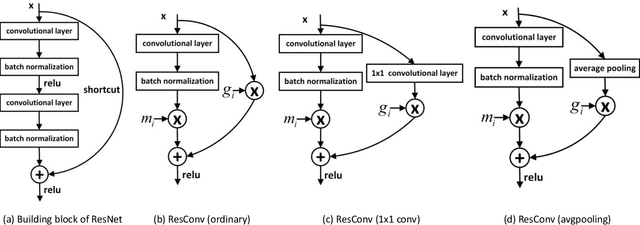
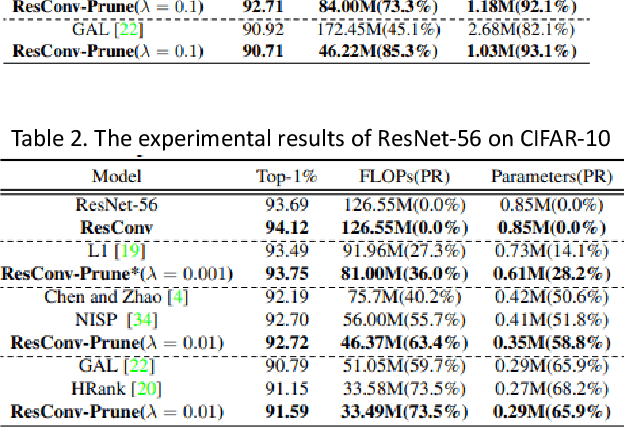
In order to deploy deep convolutional neural networks (CNNs) on resource-limited devices, many model pruning methods for filters and weights have been developed, while only a few to layer pruning. However, compared with filter pruning and weight pruning, the compact model obtained by layer pruning has less inference time and run-time memory usage when the same FLOPs and number of parameters are pruned because of less data moving in memory. In this paper, we propose a simple layer pruning method using fusible residual convolutional block (ResConv), which is implemented by inserting shortcut connection with a trainable information control parameter into a single convolutional layer. Using ResConv structures in training can improve network accuracy and train deep plain networks, and adds no additional computation during inference process because ResConv is fused to be an ordinary convolutional layer after training. For layer pruning, we convert convolutional layers of network into ResConv with a layer scaling factor. In the training process, the L1 regularization is adopted to make the scaling factors sparse, so that unimportant layers are automatically identified and then removed, resulting in a model of layer reduction. Our pruning method achieves excellent performance of compression and acceleration over the state-of-the-arts on different datasets, and needs no retraining in the case of low pruning rate. For example, with ResNet-110, we achieve a 65.5%-FLOPs reduction by removing 55.5% of the parameters, with only a small loss of 0.13% in top-1 accuracy on CIFAR-10.