 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Infer Shape Programs Using Latent Execution Self Training
Paper and Code
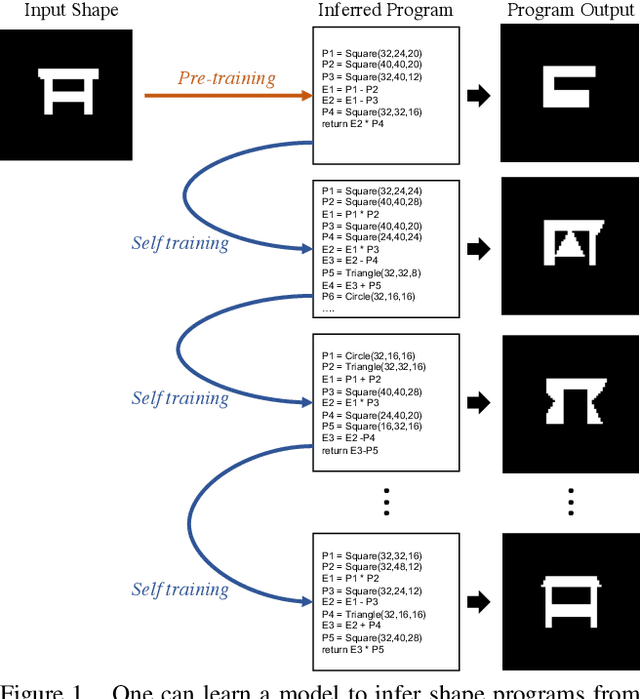
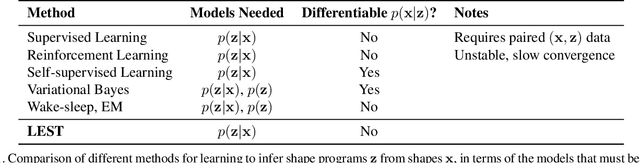
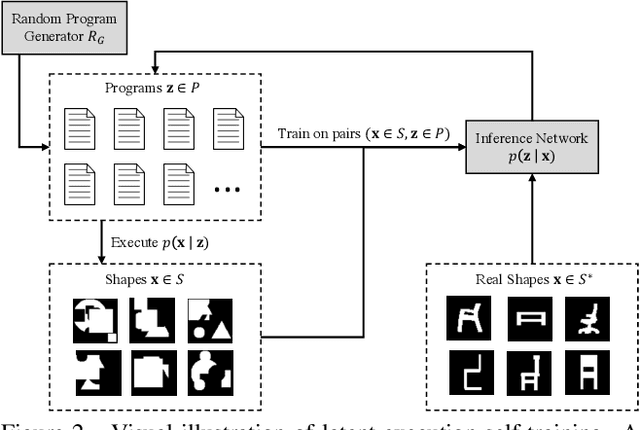
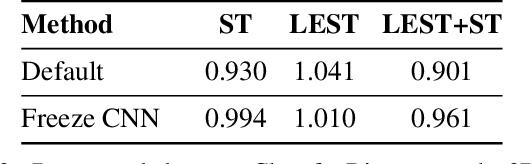
Inferring programs which generate 2D and 3D shapes is important for reverse engineering, enabling shape editing, and more. Supervised learning is hard to apply to this problem, as paired (program, shape) data rarely exists. Recent approaches use supervised pre-training with randomly-generated programs and then refine using self-supervised learning. But self-supervised learning either requires that the program execution process be differentiable or relies on reinforcement learning, which is unstable and slow to converge. In this paper, we present a new approach for learning to infer shape programs, which we call latent execution self training (LEST). As with recent prior work, LEST starts by training on randomly-generated (program, shape) pairs. As its name implies, it is based on the idea of self-training: running a model on unlabeled input shapes, treating the predicted programs as ground truth latent labels, and training again. Self-training is known to be susceptible to local minima. LEST circumvents this problem by leveraging the fact that predicted latent programs are executable: for a given shape $\mathbf{x}^* \in S^*$ and its predicted program $\mathbf{z} \in P$, we execute $\mathbf{z}$ to obtain a shape $\mathbf{x} \in S$ and train on $(\mathbf{z} \in P, \mathbf{x} \in S)$ pairs, rather than $(\mathbf{z} \in P, \mathbf{x}^* \in S^*)$ pairs. Experiments show that the distribution of executed shapes $S$ converges toward the distribution of real shapes $S^*$. We establish connections between LEST and algorithms for learning generative models, including variational Bayes, wake sleep, and expectation maximization. For constructive solid geometry and assembly-based modeling, LEST's inferred programs converge to high reconstruction accuracy significantly faster than those of reinforcement learning.