Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Reinforcement Learning is a Dataflow Problem
Paper and Code
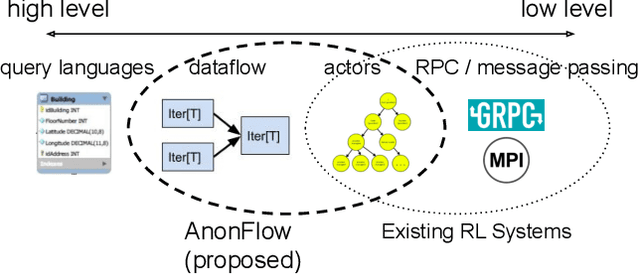
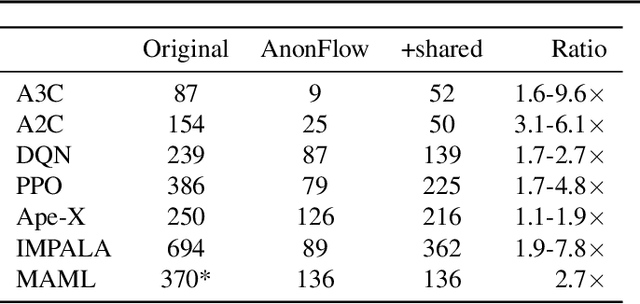
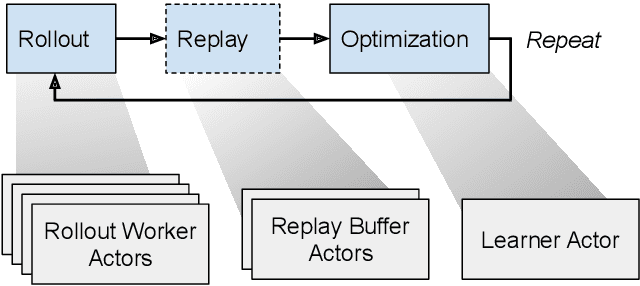
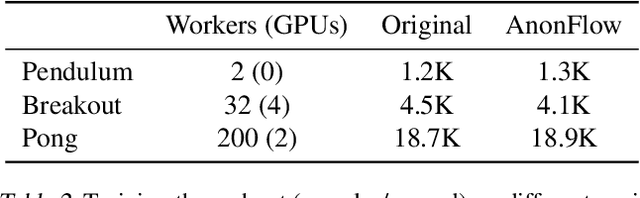
Researchers and practitioners in the field of reinforcement learning (RL) frequently leverage parallel computation, which has led to a plethora of new algorithms and systems in the last few years. In this paper, we re-examine the challenges posed by distributed RL and try to view it through the lens of an old idea: distributed dataflow. We show that viewing RL as a dataflow problem leads to highly composable and performant implementations. We propose AnonFlow, a hybrid actor-dataflow programming model for distributed RL, and validate its practicality by porting the full suite of algorithms in AnonLib, a widely-adopted distributed RL library.
* This paper has been withdrawn by the author due to the need to
compare sample throughput and training times to more dataflow-based
frameworks
View paper on