 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDADNN: Multi-Scene CTR Prediction via Domain-Aware Deep Neural Network
Paper and Code
Nov 24, 2020
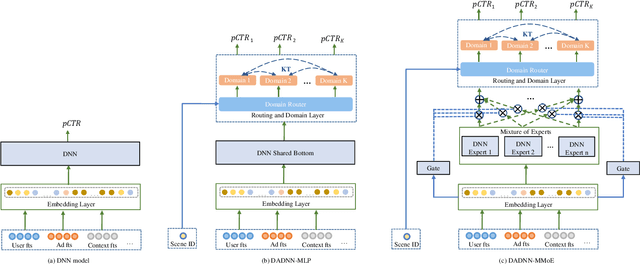
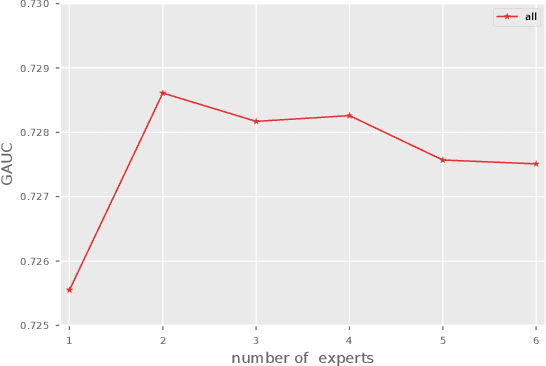
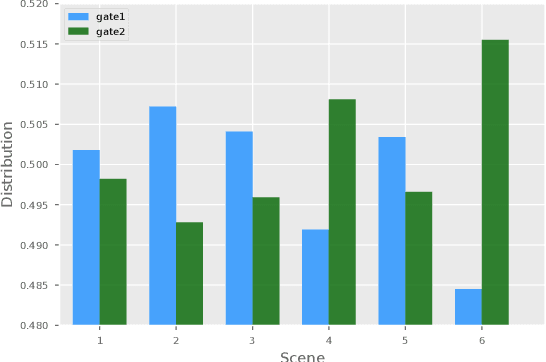
Click through rate(CTR) prediction is a core task in advertising systems. The booming e-commerce business in our company, results in a growing number of scenes. Most of them are so-called long-tail scenes, which means that the traffic of a single scene is limited, but the overall traffic is considerable. Typical studies mainly focus on serving a single scene with a well designed model. However, this method brings excessive resource consumption both on offline training and online serving. Besides, simply training a single model with data from multiple scenes ignores the characteristics of their own. To address these challenges, we propose a novel but practical model named Domain-Aware Deep Neural Network(DADNN) by serving multiple scenes with only one model. Specifically, shared bottom block among all scenes is applied to learn a common representation, while domain-specific heads maintain the characteristics of every scene. Besides, knowledge transfer is introduced to enhance the opportunity of knowledge sharing among different scenes. In this paper, we study two instances of DADNN where its shared bottom block is multilayer perceptron(MLP) and Multi-gate Mixture-of-Experts(MMoE) respectively, for which we denote as DADNN-MLP and DADNN-MMoE.Comprehensive offline experiments on a real production dataset from our company show that DADNN outperforms several state-of-the-art methods for multi-scene CTR prediction. Extensive online A/B tests reveal that DADNN-MLP contributes up to 6.7% CTR and 3.0% CPM(Cost Per Mille) promotion compared with a well-engineered DCN model. Furthermore, DADNN-MMoE outperforms DADNN-MLP with a relative improvement of 2.2% and 2.7% on CTR and CPM respectively. More importantly, DADNN utilizes a single model for multiple scenes which saves a lot of offline training and online serving resources.