 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
DADNN: Multi-Scene CTR Prediction via Domain-Aware Deep Neural Network
Nov 24, 2020
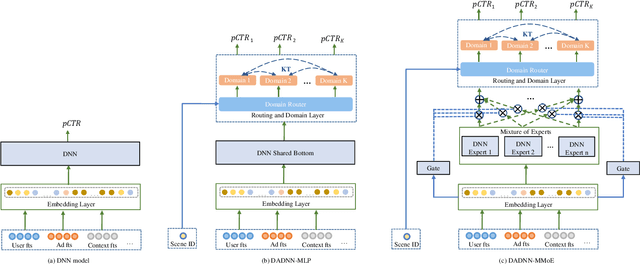
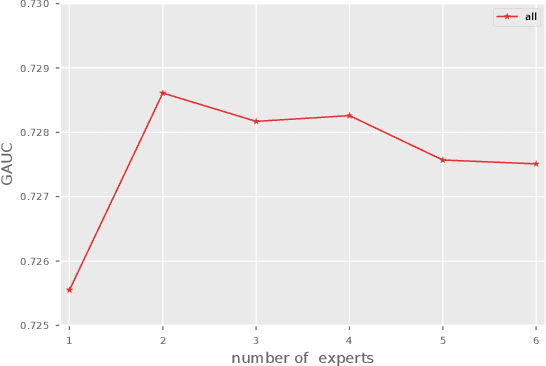
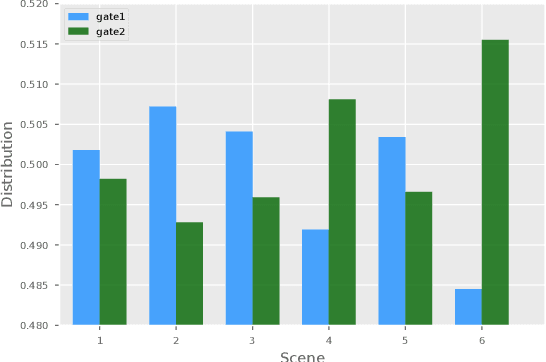
Click through rate(CTR) prediction is a core task in advertising systems. The booming e-commerce business in our company, results in a growing number of scenes. Most of them are so-called long-tail scenes, which means that the traffic of a single scene is limited, but the overall traffic is considerable. Typical studies mainly focus on serving a single scene with a well designed model. However, this method brings excessive resource consumption both on offline training and online serving. Besides, simply training a single model with data from multiple scenes ignores the characteristics of their own. To address these challenges, we propose a novel but practical model named Domain-Aware Deep Neural Network(DADNN) by serving multiple scenes with only one model. Specifically, shared bottom block among all scenes is applied to learn a common representation, while domain-specific heads maintain the characteristics of every scene. Besides, knowledge transfer is introduced to enhance the opportunity of knowledge sharing among different scenes. In this paper, we study two instances of DADNN where its shared bottom block is multilayer perceptron(MLP) and Multi-gate Mixture-of-Experts(MMoE) respectively, for which we denote as DADNN-MLP and DADNN-MMoE.Comprehensive offline experiments on a real production dataset from our company show that DADNN outperforms several state-of-the-art methods for multi-scene CTR prediction. Extensive online A/B tests reveal that DADNN-MLP contributes up to 6.7% CTR and 3.0% CPM(Cost Per Mille) promotion compared with a well-engineered DCN model. Furthermore, DADNN-MMoE outperforms DADNN-MLP with a relative improvement of 2.2% and 2.7% on CTR and CPM respectively. More importantly, DADNN utilizes a single model for multiple scenes which saves a lot of offline training and online serving resources.