 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Symbolic Representations for Video Captioning: A Case for Leveraging Inductive Biases for Vision and Language
Paper and Code
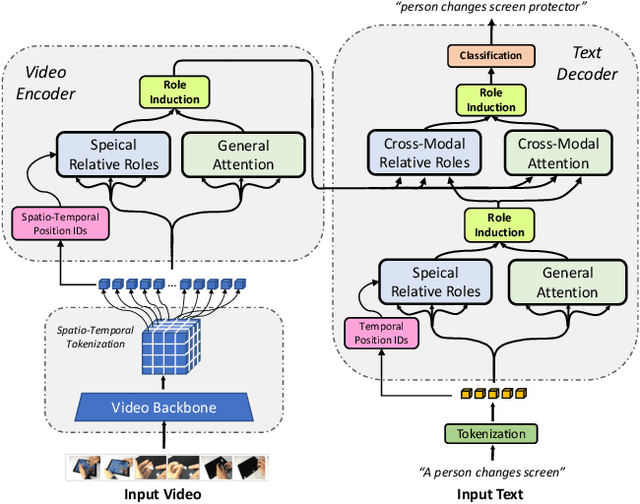
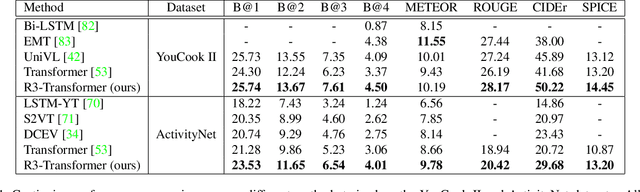
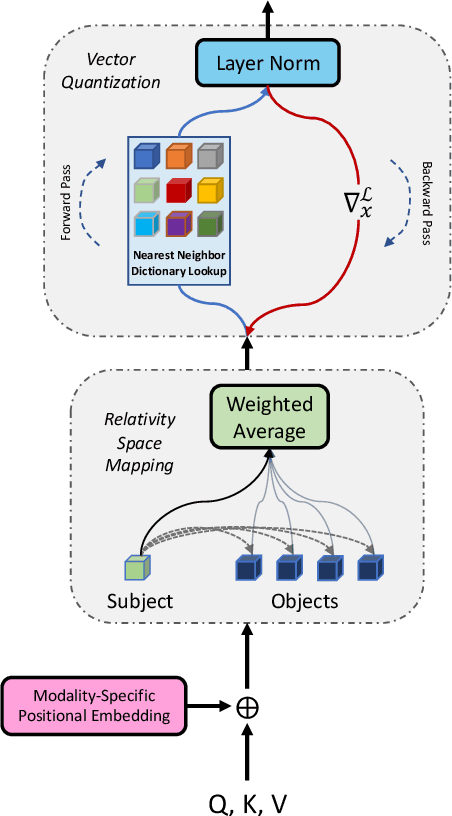
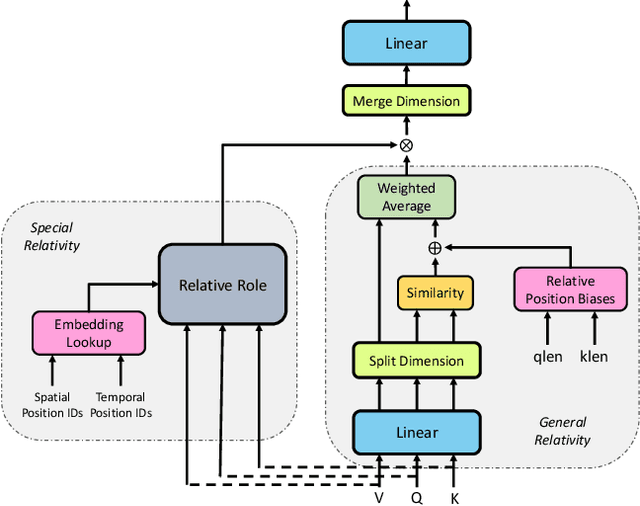
Neuro-symbolic representations have proved effective in learning structure information in vision and language. In this paper, we propose a new model architecture for learning multi-modal neuro-symbolic representations for video captioning. Our approach uses a dictionary learning-based method of learning relations between videos and their paired text descriptions. We refer to these relations as relative roles and leverage them to make each token role-aware using attention. This results in a more structured and interpretable architecture that incorporates modality-specific inductive biases for the captioning task. Intuitively, the model is able to learn spatial, temporal, and cross-modal relations in a given pair of video and text. The disentanglement achieved by our proposal gives the model more capacity to capture multi-modal structures which result in captions with higher quality for videos. Our experiments on two established video captioning datasets verifies the effectiveness of the proposed approach based on automatic metrics. We further conduct a human evaluation to measure the grounding and relevance of the generated captions and observe consistent improvement for the proposed model. The codes and trained models can be found at https://github.com/hassanhub/R3Transformer