 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum CycleGAN for Textual Sentiment Domain Adaptation with Multiple Sources
Paper and Code
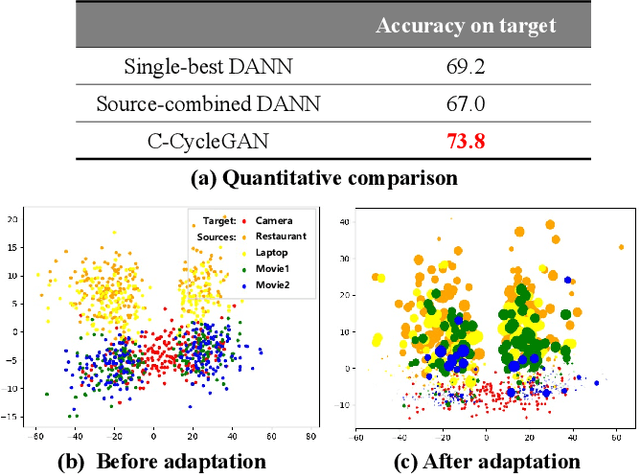
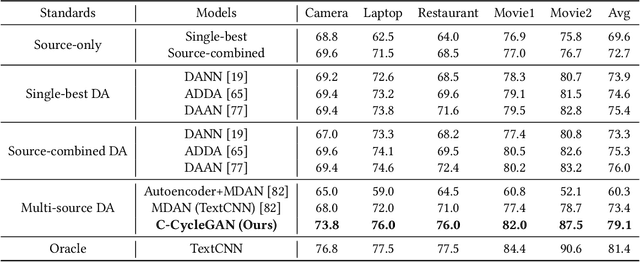
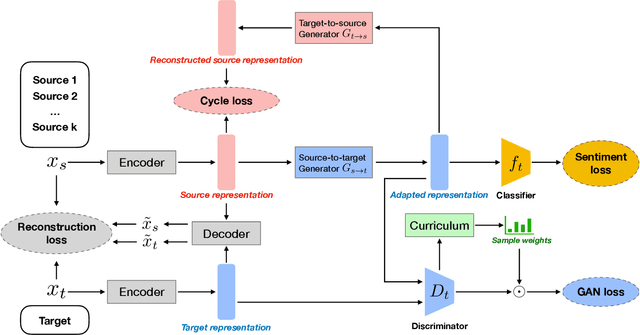
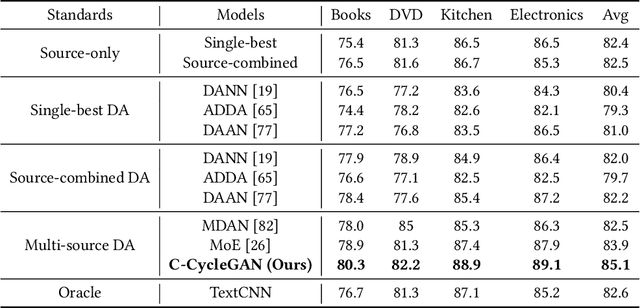
Sentiment analysis of user-generated reviews or comments on products and services on social media can help enterprises to analyze the feedback from customers and take corresponding actions for improvement. To mitigate large-scale annotations, domain adaptation (DA) provides an alternate solution by learning a transferable model from another labeled source domain. Since the labeled data may be from multiple sources, multi-source domain adaptation (MDA) would be more practical to exploit the complementary information from different domains. Existing MDA methods might fail to extract some discriminative features in the target domain that are related to sentiment, neglect the correlations of different sources as well as the distribution difference among different sub-domains even in the same source, and cannot reflect the varying optimal weighting during different training stages. In this paper, we propose an instance-level multi-source domain adaptation framework, named curriculum cycle-consistent generative adversarial network (C-CycleGAN). Specifically, C-CycleGAN consists of three components: (1) pre-trained text encoder which encodes textual input from different domains into a continuous representation space, (2) intermediate domain generator with curriculum instance-level adaptation which bridges the gap across source and target domains, and (3) task classifier trained on the intermediate domain for final sentiment classification. C-CycleGAN transfers source samples at an instance-level to an intermediate domain that is closer to target domain with sentiment semantics preserved and without losing discriminative features. Further, our dynamic instance-level weighting mechanisms can assign the optimal weights to different source samples in each training stage. We conduct extensive experiments on three benchmark datasets and achieve substantial gains over state-of-the-art approaches.