 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Reinforcement Learning Policies for Multi-Agent Control
Paper and Code
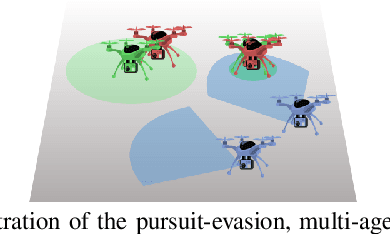
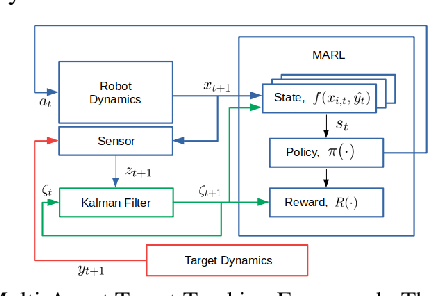
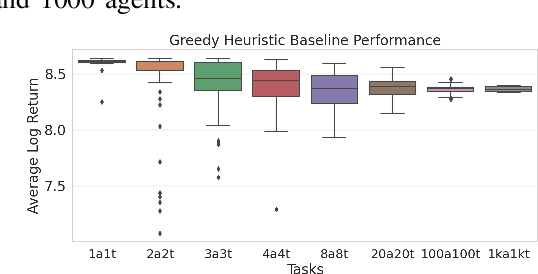
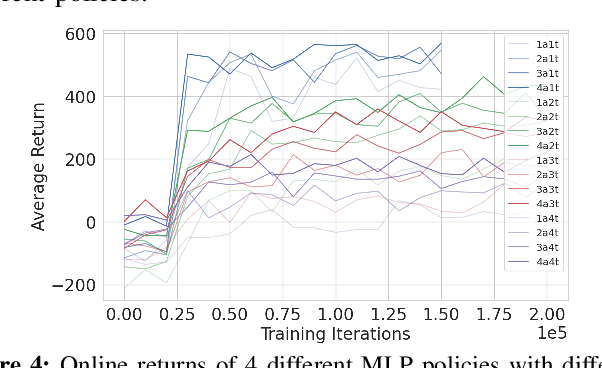
This paper develops a stochastic Multi-Agent Reinforcement Learning (MARL) method to learn control policies that can handle an arbitrary number of external agents; our policies can be executed for tasks consisting of 1000 pursuers and 1000 evaders. We model pursuers as agents with limited on-board sensing and formulate the problem as a decentralized, partially-observable Markov Decision Process. An attention mechanism is used to build a permutation and input-size invariant embedding of the observations for learning a stochastic policy and value function using techniques in entropy-regularized off-policy methods. Simulation experiments on a large number of problems show that our control policies are dramatically scalable and display cooperative behavior in spite of being executed in a decentralized fashion; our methods offer a simple solution to classical multi-agent problems using techniques in reinforcement learning.