 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeaningful Answer Generation of E-Commerce Question-Answering
Paper and Code
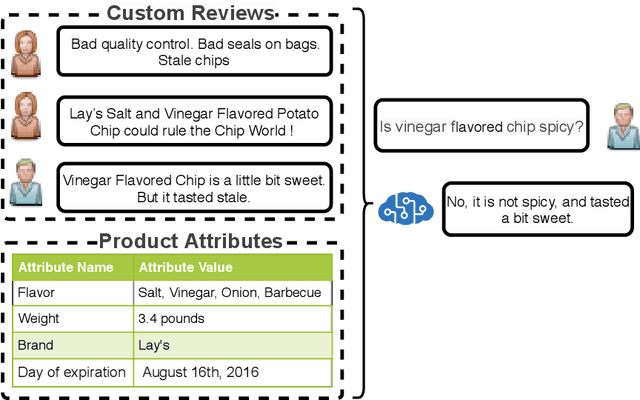
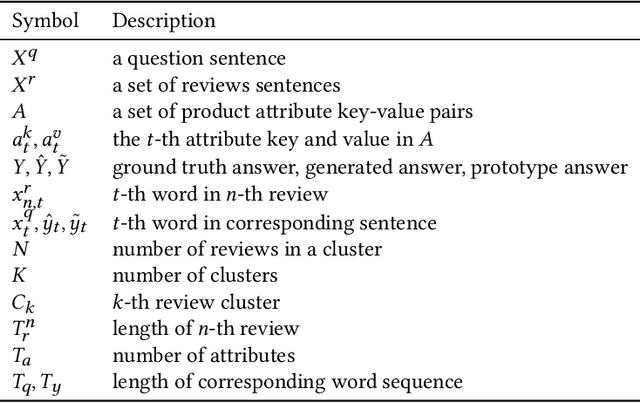
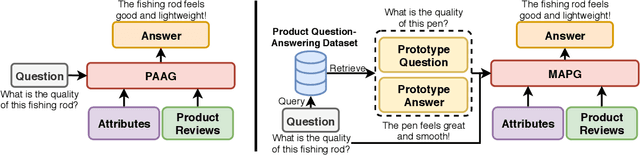
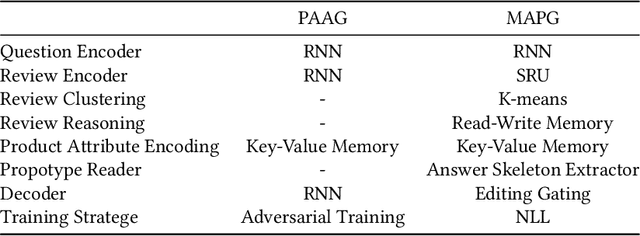
In e-commerce portals, generating answers for product-related questions has become a crucial task. In this paper, we focus on the task of product-aware answer generation, which learns to generate an accurate and complete answer from large-scale unlabeled e-commerce reviews and product attributes. However, safe answer problems pose significant challenges to text generation tasks, and e-commerce question-answering task is no exception. To generate more meaningful answers, in this paper, we propose a novel generative neural model, called the Meaningful Product Answer Generator (MPAG), which alleviates the safe answer problem by taking product reviews, product attributes, and a prototype answer into consideration. Product reviews and product attributes are used to provide meaningful content, while the prototype answer can yield a more diverse answer pattern. To this end, we propose a novel answer generator with a review reasoning module and a prototype answer reader. Our key idea is to obtain the correct question-aware information from a large scale collection of reviews and learn how to write a coherent and meaningful answer from an existing prototype answer. To be more specific, we propose a read-and-write memory consisting of selective writing units to conduct reasoning among these reviews. We then employ a prototype reader consisting of comprehensive matching to extract the answer skeleton from the prototype answer. Finally, we propose an answer editor to generate the final answer by taking the question and the above parts as input. Conducted on a real-world dataset collected from an e-commerce platform, extensive experimental results show that our model achieves state-of-the-art performance in terms of both automatic metrics and human evaluations. Human evaluation also demonstrates that our model can consistently generate specific and proper answers.