Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotically Optimal Information-Directed Sampling
Paper and Code
Nov 11, 2020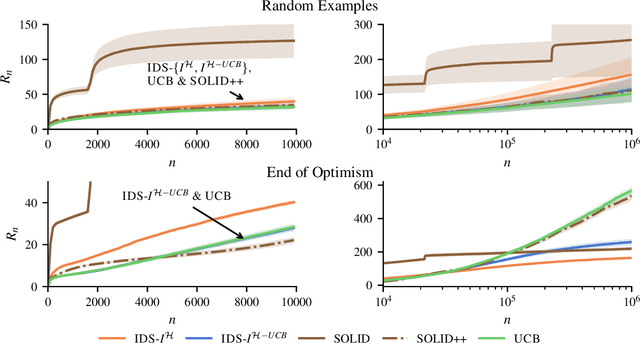
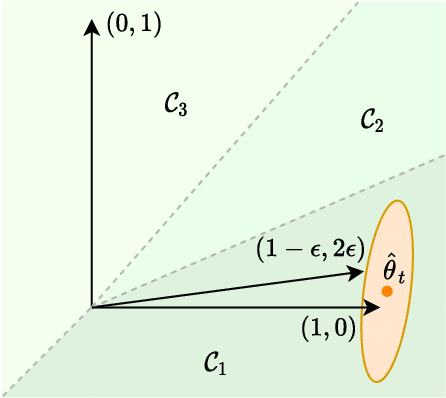

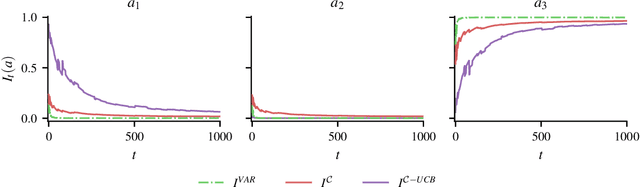
We introduce a computationally efficient algorithm for finite stochastic linear bandits. The approach is based on the frequentist information-directed sampling (IDS) framework, with an information gain potential that is derived directly from the asymptotic regret lower bound. We establish frequentist regret bounds, which show that the proposed algorithm is both asymptotically optimal and worst-case rate optimal in finite time. Our analysis sheds light on how IDS trades off regret and information to incrementally solve the semi-infinite concave program that defines the optimal asymptotic regret. Along the way, we uncover interesting connections towards a recently proposed two-player game approach and the Bayesian IDS algorithm.
View paper on