 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Deep Compressible Covariance Pooling for Aerial Scene Categorization
Paper and Code
Nov 11, 2020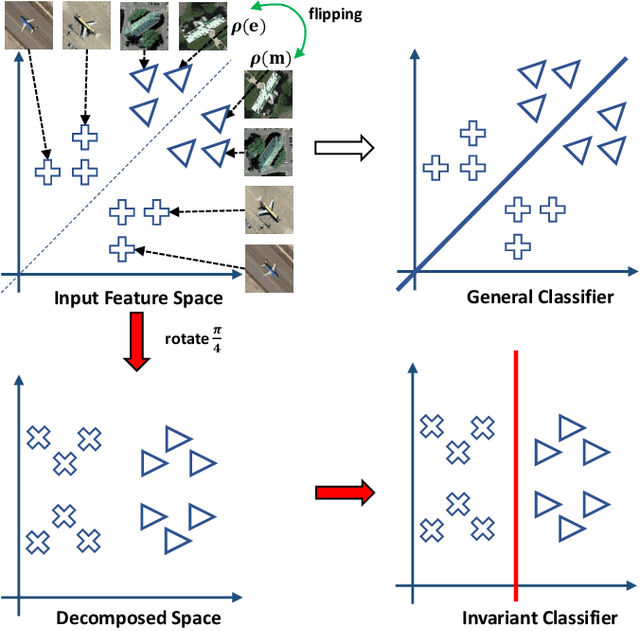
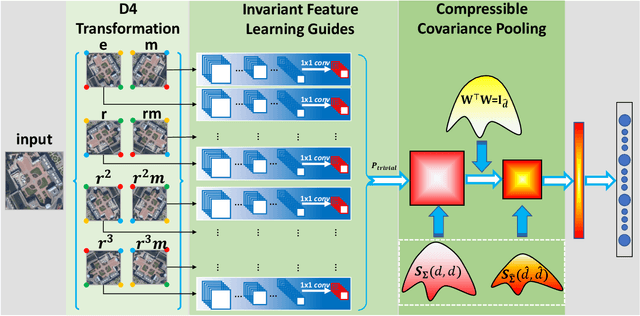
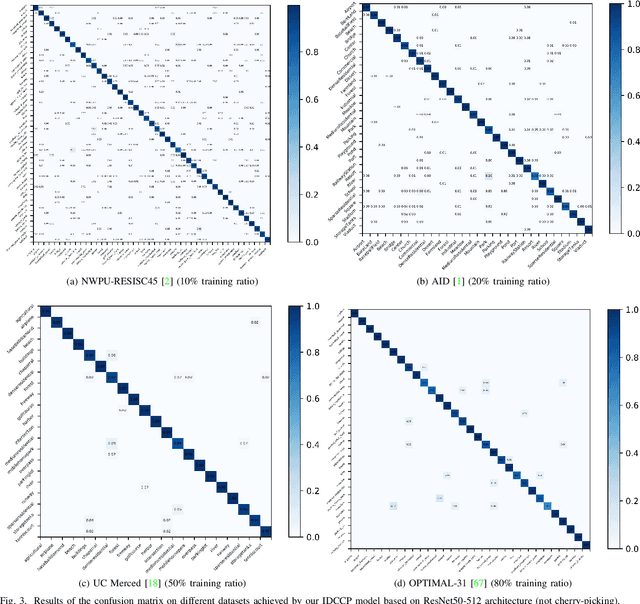
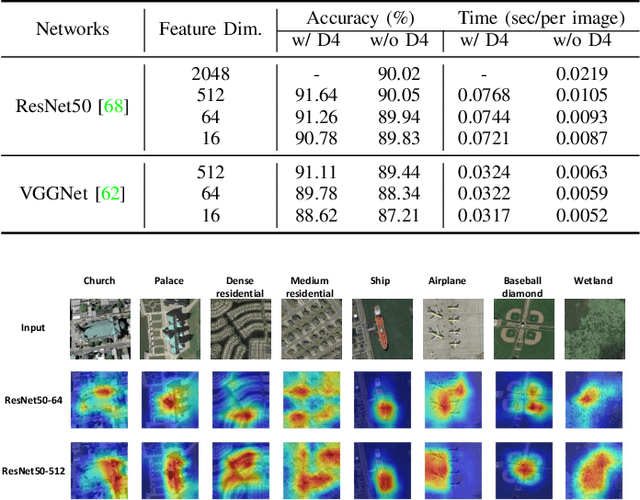
Learning discriminative and invariant feature representation is the key to visual image categorization. In this article, we propose a novel invariant deep compressible covariance pooling (IDCCP) to solve nuisance variations in aerial scene categorization. We consider transforming the input image according to a finite transformation group that consists of multiple confounding orthogonal matrices, such as the D4 group. Then, we adopt a Siamese-style network to transfer the group structure to the representation space, where we can derive a trivial representation that is invariant under the group action. The linear classifier trained with trivial representation will also be possessed with invariance. To further improve the discriminative power of representation, we extend the representation to the tensor space while imposing orthogonal constraints on the transformation matrix to effectively reduce feature dimensions. We conduct extensive experiments on the publicly released aerial scene image data sets and demonstrate the superiority of this method compared with state-of-the-art methods. In particular, with using ResNet architecture, our IDCCP model can reduce the dimension of the tensor representation by about 98% without sacrificing accuracy (i.e., <0.5%).