 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Restricted Streaming Recurrent Neural Network Transducer
Paper and Code
Nov 05, 2020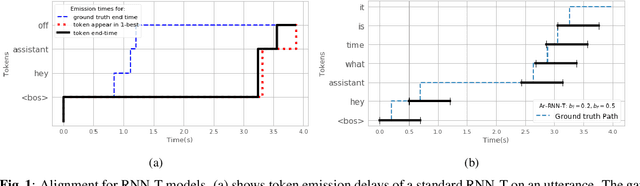
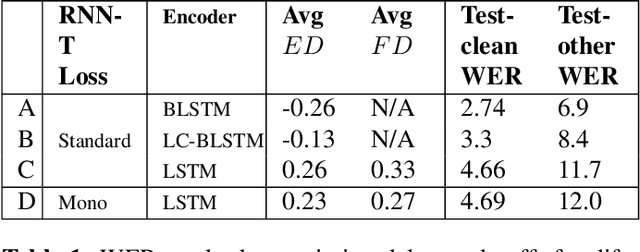
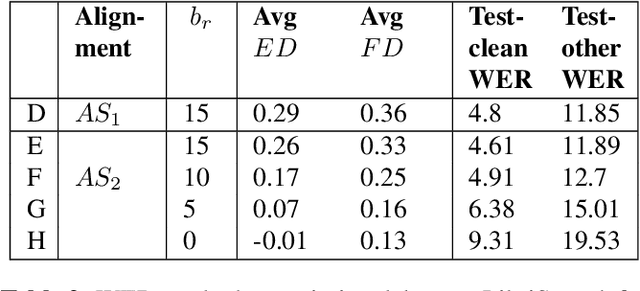
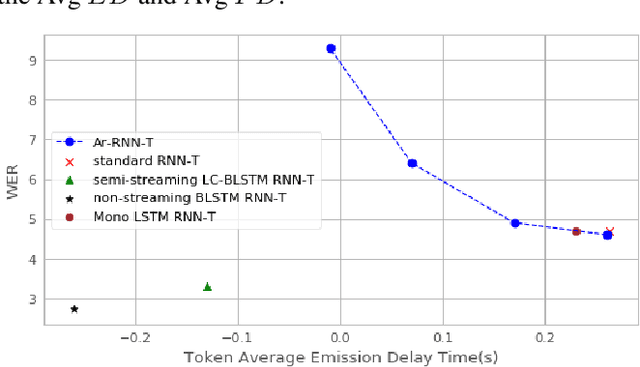
There is a growing interest in the speech community in developing Recurrent Neural Network Transducer (RNN-T) models for automatic speech recognition (ASR) applications. RNN-T is trained with a loss function that does not enforce temporal alignment of the training transcripts and audio. As a result, RNN-T models built with uni-directional long short term memory (LSTM) encoders tend to wait for longer spans of input audio, before streaming already decoded ASR tokens. In this work, we propose a modification to the RNN-T loss function and develop Alignment Restricted RNN-T (Ar-RNN-T) models, which utilize audio-text alignment information to guide the loss computation. We compare the proposed method with existing works, such as monotonic RNN-T, on LibriSpeech and in-house datasets. We show that the Ar-RNN-T loss provides a refined control to navigate the trade-offs between the token emission delays and the Word Error Rate (WER). The Ar-RNN-T models also improve downstream applications such as the ASR End-pointing by guaranteeing token emissions within any given range of latency. Moreover, the Ar-RNN-T loss allows for bigger batch sizes and 4 times higher throughput for our LSTM model architecture, enabling faster training and convergence on GPUs.