 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsodic Representation Learning and Contextual Sampling for Neural Text-to-Speech
Paper and Code
Nov 04, 2020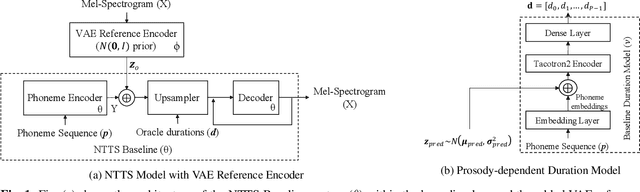
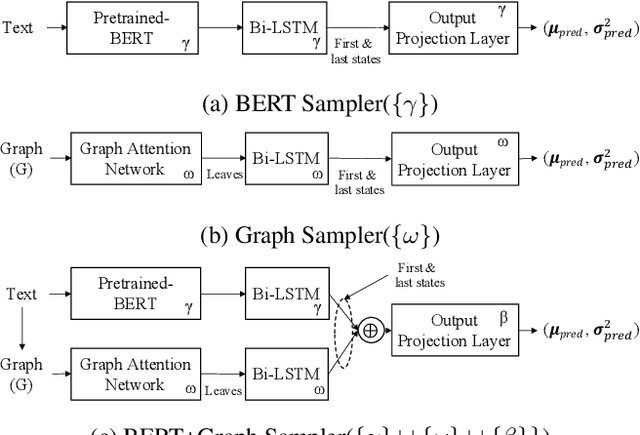
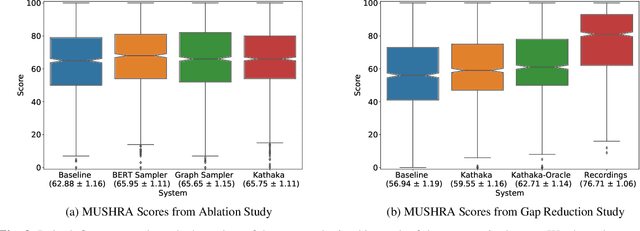
In this paper, we introduce Kathaka, a model trained with a novel two-stage training process for neural speech synthesis with contextually appropriate prosody. In Stage I, we learn a prosodic distribution at the sentence level from mel-spectrograms available during training. In Stage II, we propose a novel method to sample from this learnt prosodic distribution using the contextual information available in text. To do this, we use BERT on text, and graph-attention networks on parse trees extracted from text. We show a statistically significant relative improvement of $13.2\%$ in naturalness over a strong baseline when compared to recordings. We also conduct an ablation study on variations of our sampling technique, and show a statistically significant improvement over the baseline in each case.