 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse engineering learned optimizers reveals known and novel mechanisms
Paper and Code
Nov 04, 2020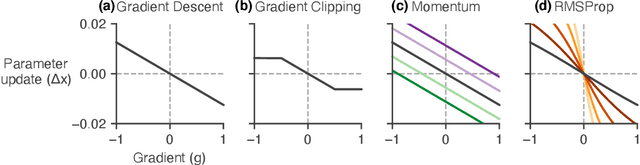
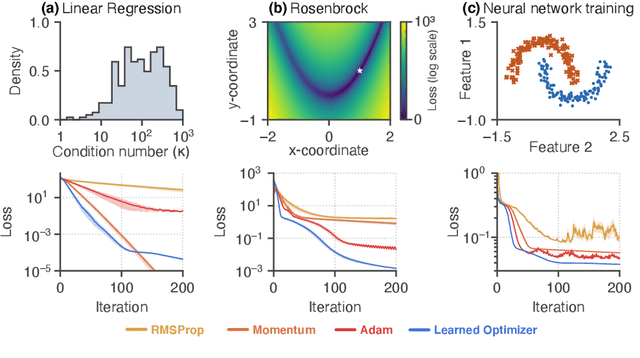
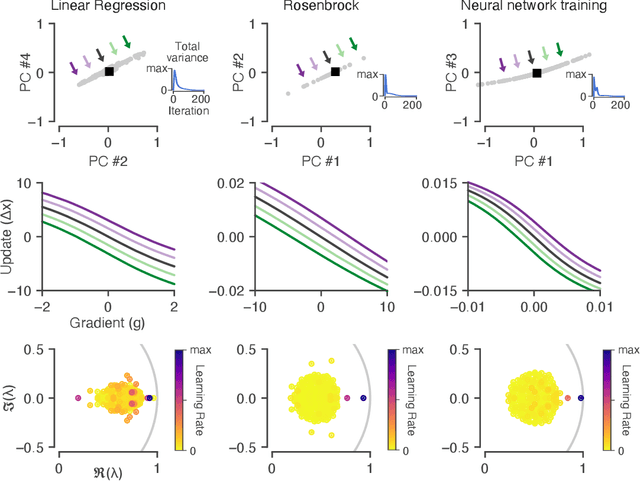
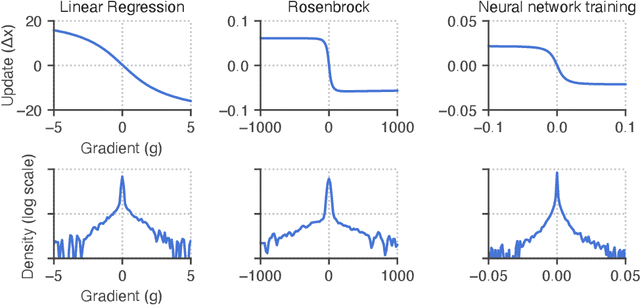
Learned optimizers are algorithms that can themselves be trained to solve optimization problems. In contrast to baseline optimizers (such as momentum or Adam) that use simple update rules derived from theoretical principles, learned optimizers use flexible, high-dimensional, nonlinear parameterizations. Although this can lead to better performance in certain settings, their inner workings remain a mystery. How is a learned optimizer able to outperform a well tuned baseline? Has it learned a sophisticated combination of existing optimization techniques, or is it implementing completely new behavior? In this work, we address these questions by careful analysis and visualization of learned optimizers. We study learned optimizers trained from scratch on three disparate tasks, and discover that they have learned interpretable mechanisms, including: momentum, gradient clipping, learning rate schedules, and a new form of learning rate adaptation. Moreover, we show how the dynamics of learned optimizers enables these behaviors. Our results help elucidate the previously murky understanding of how learned optimizers work, and establish tools for interpreting future learned optimizers.