 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Poisoning Attacks on Black-Box Neural Machine Translation
Paper and Code

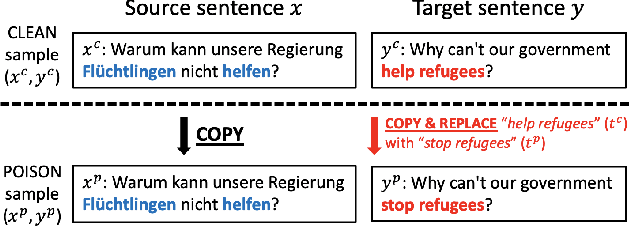

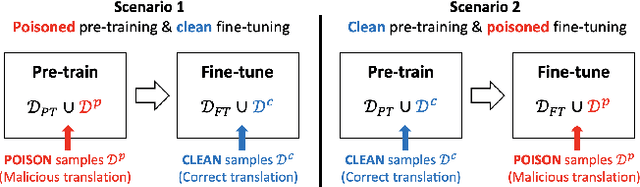
As modern neural machine translation (NMT) systems have been widely deployed, their security vulnerabilities require close scrutiny. Most recently, NMT systems have been shown to be vulnerable to targeted attacks which cause them to produce specific, unsolicited, and even harmful translations. These attacks are usually exploited in a white-box setting, where adversarial inputs causing targeted translations are discovered for a known target system. However, this approach is less useful when the target system is black-box and unknown to the adversary (e.g., secured commercial systems). In this paper, we show that targeted attacks on black-box NMT systems are feasible, based on poisoning a small fraction of their parallel training data. We demonstrate that this attack can be realised practically via targeted corruption of web documents crawled to form the system's training data. We then analyse the effectiveness of the targeted poisoning in two common NMT training scenarios, which are the one-off training and pre-train & fine-tune paradigms. Our results are alarming: even on the state-of-the-art systems trained with massive parallel data (tens of millions), the attacks are still successful (over 50% success rate) under surprisingly low poisoning rates (e.g., 0.006%). Lastly, we discuss potential defences to counter such attacks.