 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Dynamic Context for Multi-path Trajectory Prediction
Paper and Code

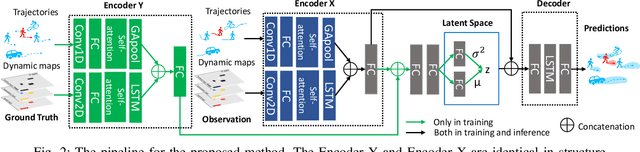
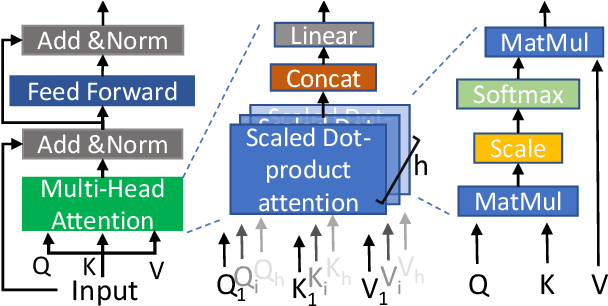
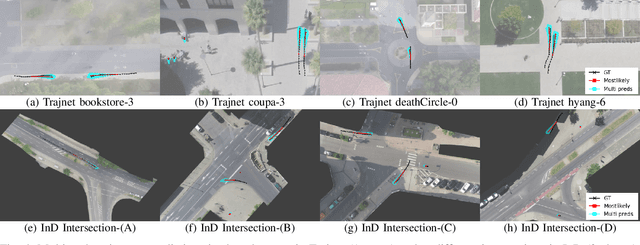
To accurately predict future positions of different agents in traffic scenarios is crucial for safely deploying intelligent autonomous systems in the real-world environment. However, it remains a challenge due to the behavior of a target agent being affected by other agents dynamically, and there being more than one socially possible paths the agent could take. In this paper, we propose a novel framework, named Dynamic Context Encoder Network (DCENet). In our framework, first, the spatial context between agents is explored by using self-attention architectures. Then, two LSTM encoders are trained to learn temporal context between steps by taking the observed trajectories and the extracted dynamic spatial context as input, respectively. The spatial-temporal context is encoded into a latent space using a Conditional Variational Auto-Encoder (CVAE) module. Finally, a set of future trajectories for each agent is predicted conditioned on the learned spatial-temporal context by sampling from the latent space, repeatedly. DCENet is evaluated on the largest and most challenging trajectory forecasting benchmark Trajnet and reports a new state-of-the-art performance. It also demonstrates superior performance evaluated on the benchmark InD for mixed traffic at intersections. A series of ablation studies are conducted to validate the effectiveness of each proposed module. Our code is available at https://github.com/wtliao/DCENet.