 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion recognition by fusing time synchronous and time asynchronous representations
Paper and Code
Oct 27, 2020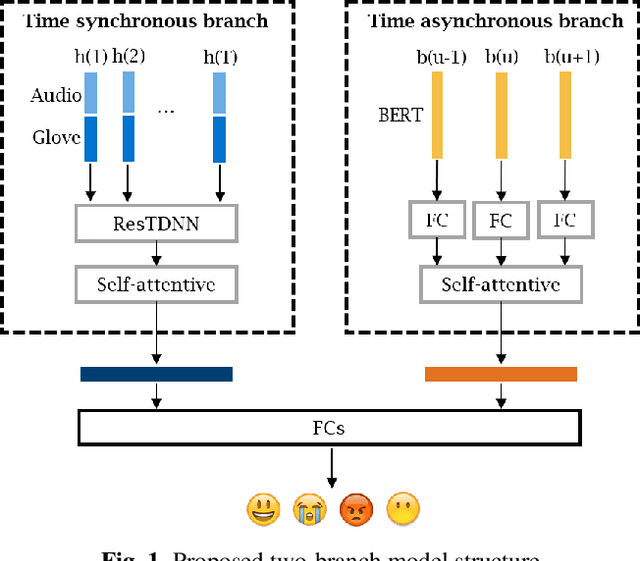



In this paper, a novel two-branch neural network model structure is proposed for multimodal emotion recognition, which consists of a time synchronous branch (TSB) and a time asynchronous branch (TAB). To capture correlations between each word and its acoustic realisation, the TSB combines speech and text modalities at each input window frame and then does pooling across time to form a single embedding vector. The TAB, by contrast, provides cross-utterance information by integrating sentence text embeddings from a number of context utterances into another embedding vector. The final emotion classification uses both the TSB and the TAB embeddings. Experimental results on the IEMOCAP dataset demonstrate that the two-branch structure achieves state-of-the-art results in 4-way classification with all common test setups. When using automatic speech recognition (ASR) output instead of manually transcribed reference text, it is shown that the cross-utterance information considerably improves the robustness against ASR errors. Furthermore, by incorporating an extra class for all the other emotions, the final 5-way classification system with ASR hypotheses can be viewed as a prototype for more realistic emotion recognition systems.