 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$P^2$ Net: Augmented Parallel-Pyramid Net for Attention Guided Pose Estimation
Paper and Code
Oct 26, 2020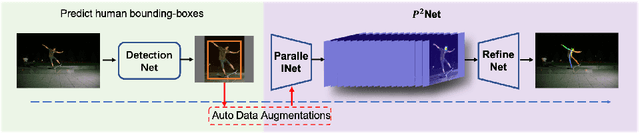

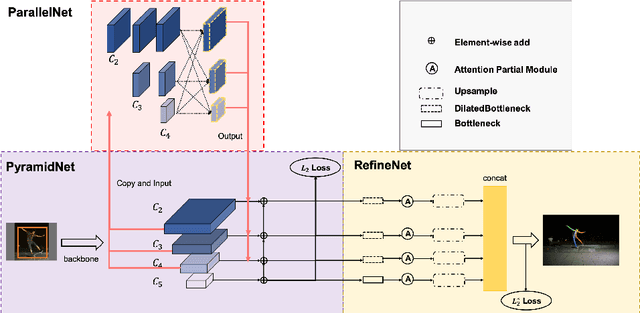
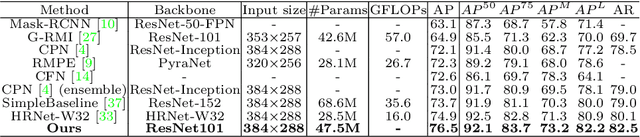
We propose an augmented Parallel-Pyramid Net ($P^2~Net$) with feature refinement by dilated bottleneck and attention module. During data preprocessing, we proposed a differentiable auto data augmentation ($DA^2$) method. We formulate the problem of searching data augmentaion policy in a differentiable form, so that the optimal policy setting can be easily updated by back propagation during training. $DA^2$ improves the training efficiency. A parallel-pyramid structure is followed to compensate the information loss introduced by the network. We innovate two fusion structures, i.e. Parallel Fusion and Progressive Fusion, to process pyramid features from backbone network. Both fusion structures leverage the advantages of spatial information affluence at high resolution and semantic comprehension at low resolution effectively. We propose a refinement stage for the pyramid features to further boost the accuracy of our network. By introducing dilated bottleneck and attention module, we increase the receptive field for the features with limited complexity and tune the importance to different feature channels. To further refine the feature maps after completion of feature extraction stage, an Attention Module ($AM$) is defined to extract weighted features from different scale feature maps generated by the parallel-pyramid structure. Compared with the traditional up-sampling refining, $AM$ can better capture the relationship between channels. Experiments corroborate the effectiveness of our proposed method. Notably, our method achieves the best performance on the challenging MSCOCO and MPII datasets.