 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Training for Monocular Human Mesh Recovery
Paper and Code
Oct 27, 2020
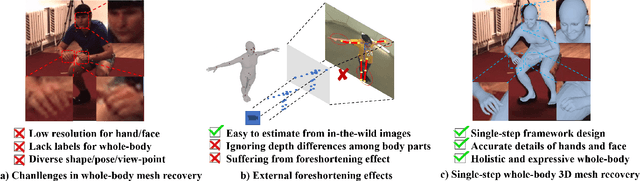
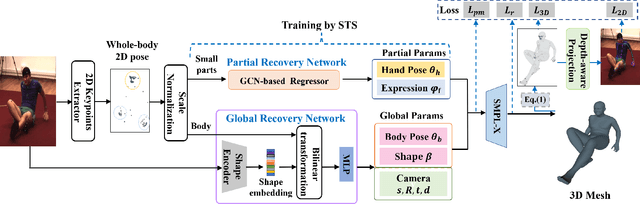
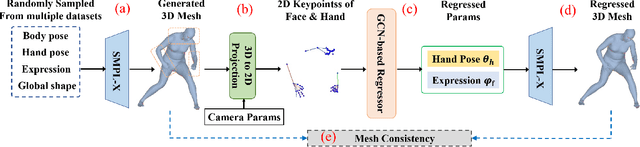
Recovering 3D human mesh from monocular images is a popular topic in computer vision and has a wide range of applications. This paper aims to estimate 3D mesh of multiple body parts (e.g., body, hands) with large-scale differences from a single RGB image. Existing methods are mostly based on iterative optimization, which is very time-consuming. We propose to train a single-shot model to achieve this goal. The main challenge is lacking training data that have complete 3D annotations of all body parts in 2D images. To solve this problem, we design a multi-branch framework to disentangle the regression of different body properties, enabling us to separate each component's training in a synthetic training manner using unpaired data available. Besides, to strengthen the generalization ability, most existing methods have used in-the-wild 2D pose datasets to supervise the estimated 3D pose via 3D-to-2D projection. However, we observe that the commonly used weak-perspective model performs poorly in dealing with the external foreshortening effect of camera projection. Therefore, we propose a depth-to-scale (D2S) projection to incorporate the depth difference into the projection function to derive per-joint scale variants for more proper supervision. The proposed method outperforms previous methods on the CMU Panoptic Studio dataset according to the evaluation results and achieves comparable results on the Human3.6M body and STB hand benchmarks. More impressively, the performance in close shot images gets significantly improved using the proposed D2S projection for weak supervision, while maintains obvious superiority in computational efficiency.