 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Metadata-Aware Document Categorization under Weak Supervision
Paper and Code

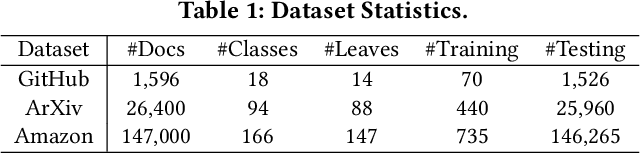
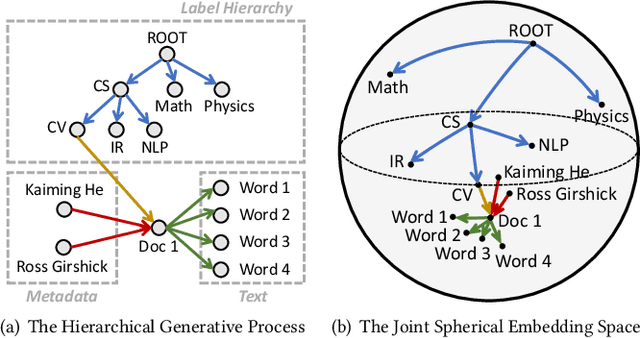
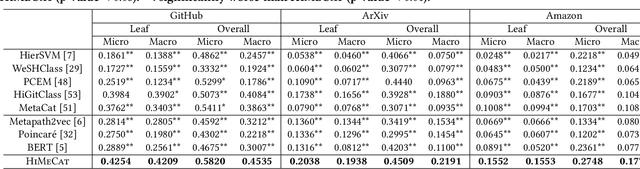
Categorizing documents into a given label hierarchy is intuitively appealing due to the ubiquity of hierarchical topic structures in massive text corpora. Although related studies have achieved satisfying performance in fully supervised hierarchical document classification, they usually require massive human-annotated training data and only utilize text information. However, in many domains, (1) annotations are quite expensive where very few training samples can be acquired; (2) documents are accompanied by metadata information. Hence, this paper studies how to integrate the label hierarchy, metadata, and text signals for document categorization under weak supervision. We develop HiMeCat, an embedding-based generative framework for our task. Specifically, we propose a novel joint representation learning module that allows simultaneous modeling of category dependencies, metadata information and textual semantics, and we introduce a data augmentation module that hierarchically synthesizes training documents to complement the original, small-scale training set. Our experiments demonstrate a consistent improvement of HiMeCat over competitive baselines and validate the contribution of our representation learning and data augmentation modules.