 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustBench: a standardized adversarial robustness benchmark
Paper and Code
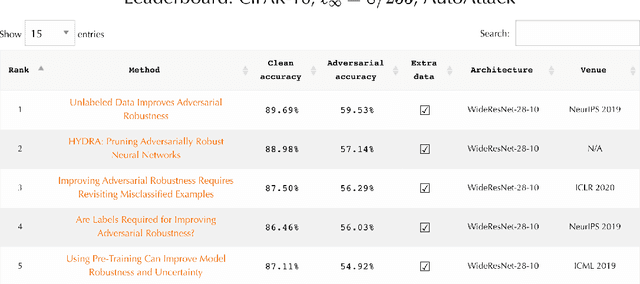
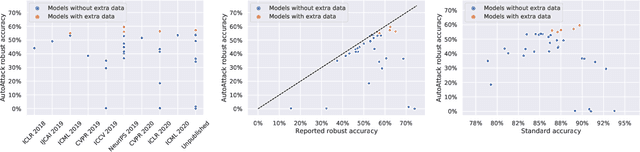
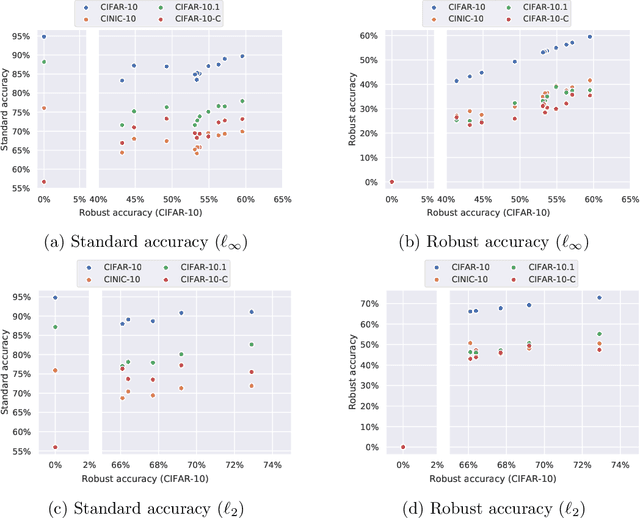
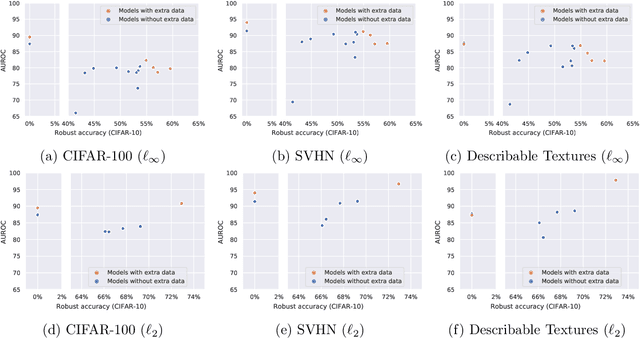
Evaluation of adversarial robustness is often error-prone leading to overestimation of the true robustness of models. While adaptive attacks designed for a particular defense are a way out of this, there are only approximate guidelines on how to perform them. Moreover, adaptive evaluations are highly customized for particular models, which makes it difficult to compare different defenses. Our goal is to establish a standardized benchmark of adversarial robustness, which as accurately as possible reflects the robustness of the considered models within a reasonable computational budget. This requires to impose some restrictions on the admitted models to rule out defenses that only make gradient-based attacks ineffective without improving actual robustness. We evaluate robustness of models for our benchmark with AutoAttack, an ensemble of white- and black-box attacks which was recently shown in a large-scale study to improve almost all robustness evaluations compared to the original publications. Our leaderboard, hosted at http://robustbench.github.io/, aims at reflecting the current state of the art on a set of well-defined tasks in $\ell_\infty$- and $\ell_2$-threat models with possible extensions in the future. Additionally, we open-source the library http://github.com/RobustBench/robustbench that provides unified access to state-of-the-art robust models to facilitate their downstream applications. Finally, based on the collected models, we analyze general trends in $\ell_p$-robustness and its impact on other tasks such as robustness to various distribution shifts and out-of-distribution detection.