 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Reinforcement Learning in NOMA-aided UAV Networks for Cellular Offloading
Paper and Code
Oct 18, 2020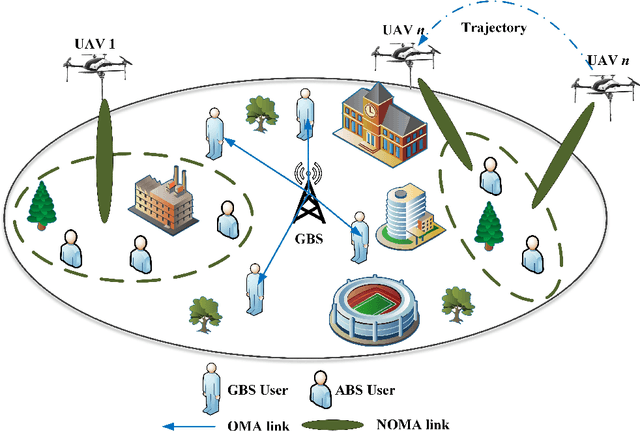
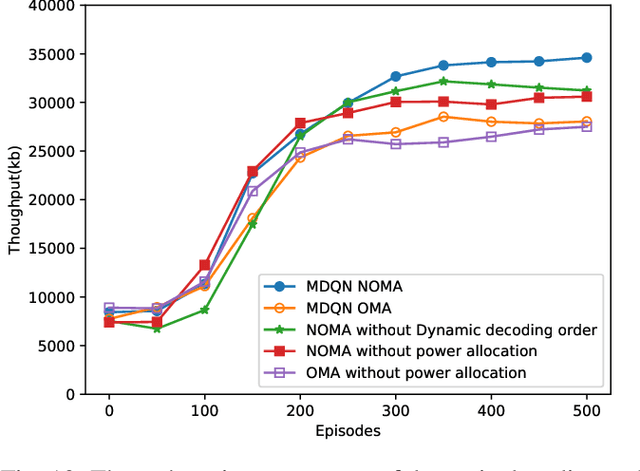
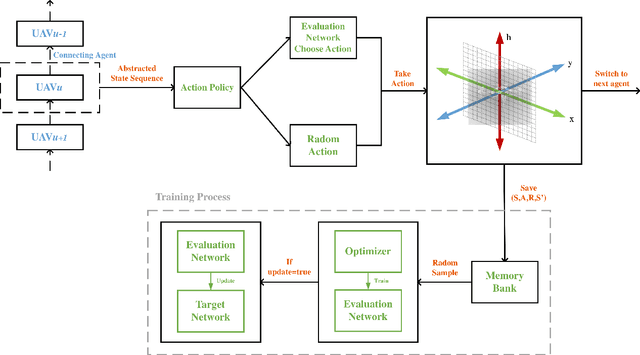
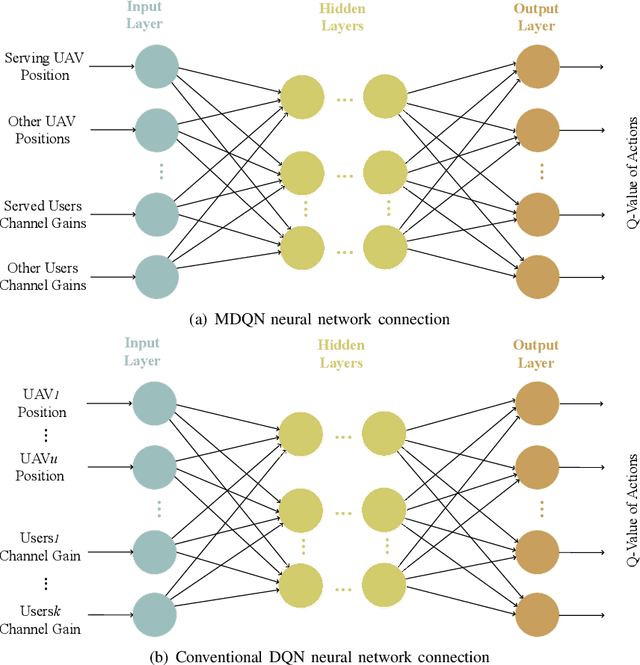
A novel framework is proposed for cellular offloading with the aid of multiple unmanned aerial vehicles (UAVs), while the non-orthogonal multiple access (NOMA) technique is employed at each UAV to further improve the spectrum efficiency of the wireless network. The optimization problem of joint three-dimensional (3D) trajectory design and power allocation is formulated for maximizing the throughput. Since ground mobile users are considered as roaming continuously, the UAVs need to be re-deployed timely based on the movement of users. In an effort to solve this pertinent dynamic problem, a K-means based clustering algorithm is first adopted for periodically partitioning users. Afterward, a mutual deep Q-network (MDQN) algorithm is proposed to jointly determine the optimal 3D trajectory and power allocation of UAVs. In contrast to the conventional DQN algorithm, the MDQN algorithm enables the experience of multi-agent to be input into a shared neural network to shorten the training time with the assistance of state abstraction. Numerical results demonstrate that: 1) the proposed MDQN algorithm is capable of converging under minor constraints and has a faster convergence rate than the conventional DQN algorithm in the multi-agent case; 2) The achievable sum rate of the NOMA enhanced UAV network is 23% superior to the case of orthogonal multiple access (OMA); 3) By designing the optimal 3D trajectory of UAVs with the aid of the MDON algorithm, the sum rate of the network enjoys 142% and 56% gains than that of invoking the circular trajectory and the 2D trajectory, respectively.