 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorFlow Lite Micro: Embedded Machine Learning on TinyML Systems
Paper and Code
Oct 20, 2020

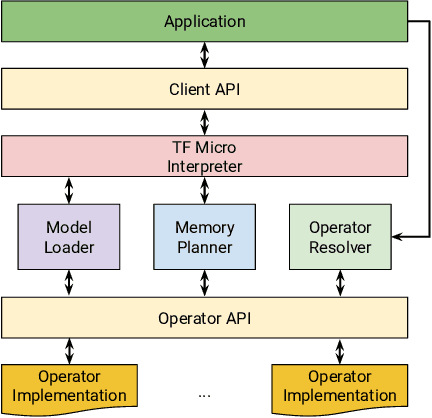
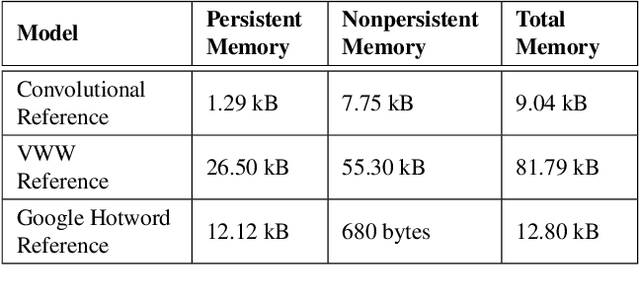
Deep learning inference on embedded devices is a burgeoning field with myriad applications because tiny embedded devices are omnipresent. But we must overcome major challenges before we can benefit from this opportunity. Embedded processors are severely resource constrained. Their nearest mobile counterparts exhibit at least a 100---1,000x difference in compute capability, memory availability, and power consumption. As a result, the machine-learning (ML) models and associated ML inference framework must not only execute efficiently but also operate in a few kilobytes of memory. Also, the embedded devices' ecosystem is heavily fragmented. To maximize efficiency, system vendors often omit many features that commonly appear in mainstream systems, including dynamic memory allocation and virtual memory, that allow for cross-platform interoperability. The hardware comes in many flavors (e.g., instruction-set architecture and FPU support, or lack thereof). We introduce TensorFlow Lite Micro (TF Micro), an open-source ML inference framework for running deep-learning models on embedded systems. TF Micro tackles the efficiency requirements imposed by embedded-system resource constraints and the fragmentation challenges that make cross-platform interoperability nearly impossible. The framework adopts a unique interpreter-based approach that provides flexibility while overcoming these challenges. This paper explains the design decisions behind TF Micro and describes its implementation details. Also, we present an evaluation to demonstrate its low resource requirement and minimal run-time performance overhead.