 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogueTRM: Exploring the Intra- and Inter-Modal Emotional Behaviors in the Conversation
Paper and Code


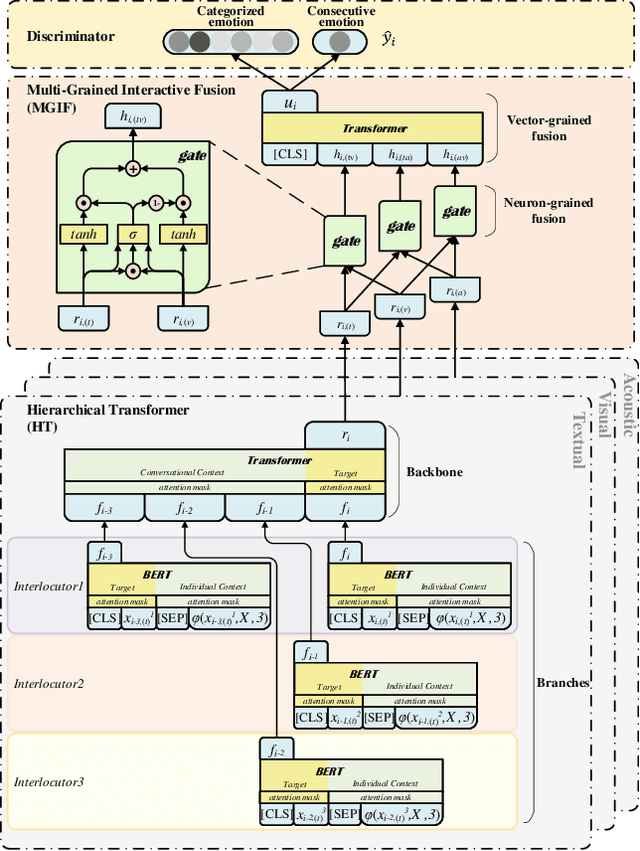
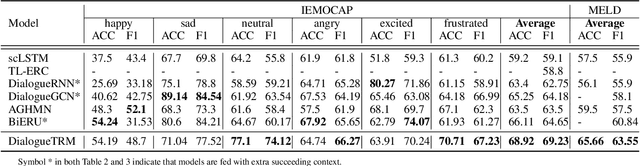
Emotion Recognition in Conversations (ERC) is essential for building empathetic human-machine systems. Existing studies on ERC primarily focus on summarizing the context information in a conversation, however, ignoring the differentiated emotional behaviors within and across different modalities. Designing appropriate strategies that fit the differentiated multi-modal emotional behaviors can produce more accurate emotional predictions. Thus, we propose the DialogueTransformer to explore the differentiated emotional behaviors from the intra- and inter-modal perspectives. For intra-modal, we construct a novel Hierarchical Transformer that can easily switch between sequential and feed-forward structures according to the differentiated context preference within each modality. For inter-modal, we constitute a novel Multi-Grained Interactive Fusion that applies both neuron- and vector-grained feature interactions to learn the differentiated contributions across all modalities. Experimental results show that DialogueTRM outperforms the state-of-the-art by a significant margin on three benchmark datasets.