 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree-Dimensional Lip Motion Network for Text-Independent Speaker Recognition
Paper and Code
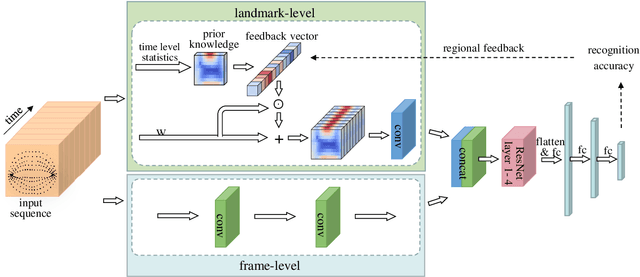
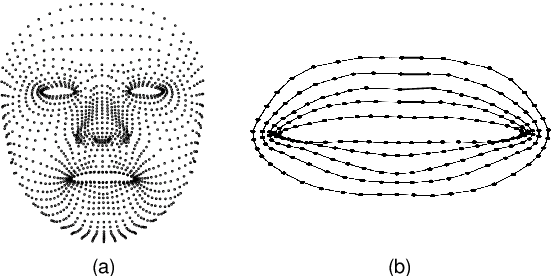

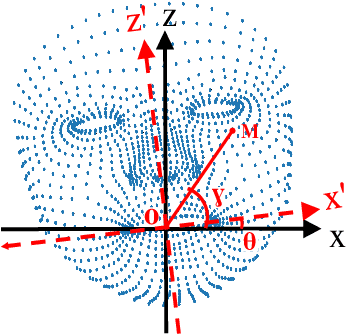
Lip motion reflects behavior characteristics of speakers, and thus can be used as a new kind of biometrics in speaker recognition. In the literature, lots of works used two-dimensional (2D) lip images to recognize speaker in a textdependent context. However, 2D lip easily suffers from various face orientations. To this end, in this work, we present a novel end-to-end 3D lip motion Network (3LMNet) by utilizing the sentence-level 3D lip motion (S3DLM) to recognize speakers in both the text-independent and text-dependent contexts. A new regional feedback module (RFM) is proposed to obtain attentions in different lip regions. Besides, prior knowledge of lip motion is investigated to complement RFM, where landmark-level and frame-level features are merged to form a better feature representation. Moreover, we present two methods, i.e., coordinate transformation and face posture correction to pre-process the LSD-AV dataset, which contains 68 speakers and 146 sentences per speaker. The evaluation results on this dataset demonstrate that our proposed 3LMNet is superior to the baseline models, i.e., LSTM, VGG-16 and ResNet-34, and outperforms the state-of-the-art using 2D lip image as well as the 3D face. The code of this work is released at https://github.com/wutong18/Three-Dimensional-Lip- Motion-Network-for-Text-Independent-Speaker-Recognition.