 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVMSMO: Learning to Generate Multimodal Summary for Video-based News Articles
Paper and Code

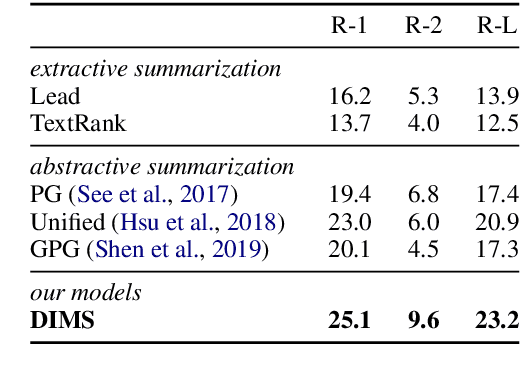
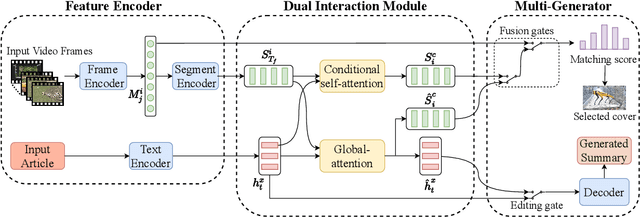
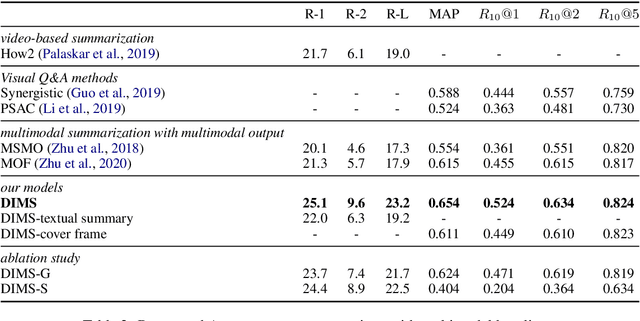
A popular multimedia news format nowadays is providing users with a lively video and a corresponding news article, which is employed by influential news media including CNN, BBC, and social media including Twitter and Weibo. In such a case, automatically choosing a proper cover frame of the video and generating an appropriate textual summary of the article can help editors save time, and readers make the decision more effectively. Hence, in this paper, we propose the task of Video-based Multimodal Summarization with Multimodal Output (VMSMO) to tackle such a problem. The main challenge in this task is to jointly model the temporal dependency of video with semantic meaning of article. To this end, we propose a Dual-Interaction-based Multimodal Summarizer (DIMS), consisting of a dual interaction module and multimodal generator. In the dual interaction module, we propose a conditional self-attention mechanism that captures local semantic information within video and a global-attention mechanism that handles the semantic relationship between news text and video from a high level. Extensive experiments conducted on a large-scale real-world VMSMO dataset show that DIMS achieves the state-of-the-art performance in terms of both automatic metrics and human evaluations.