 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Forward Propagation for Memorized Batch Normalization
Paper and Code
Oct 10, 2020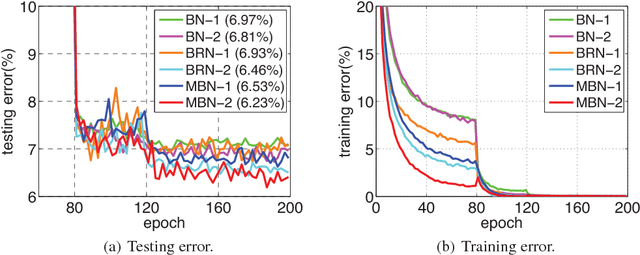

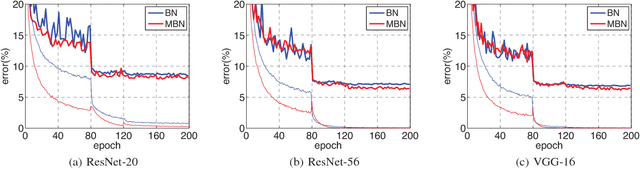

Batch Normalization (BN) has been a standard component in designing deep neural networks (DNNs). Although the standard BN can significantly accelerate the training of DNNs and improve the generalization performance, it has several underlying limitations which may hamper the performance in both training and inference. In the training stage, BN relies on estimating the mean and variance of data using a single minibatch. Consequently, BN can be unstable when the batch size is very small or the data is poorly sampled. In the inference stage, BN often uses the so called moving mean and moving variance instead of batch statistics, i.e., the training and inference rules in BN are not consistent. Regarding these issues, we propose a memorized batch normalization (MBN), which considers multiple recent batches to obtain more accurate and robust statistics. Note that after the SGD update for each batch, the model parameters will change, and the features will change accordingly, leading to the Distribution Shift before and after the update for the considered batch. To alleviate this issue, we present a simple Double-Forward scheme in MBN which can further improve the performance. Compared to related methods, the proposed MBN exhibits consistent behaviors in both training and inference. Empirical results show that the MBN based models trained with the Double-Forward scheme greatly reduce the sensitivity of data and significantly improve the generalization performance.