Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward-Biased Maximum Likelihood Estimation for Linear Stochastic Bandits
Paper and Code
Oct 08, 2020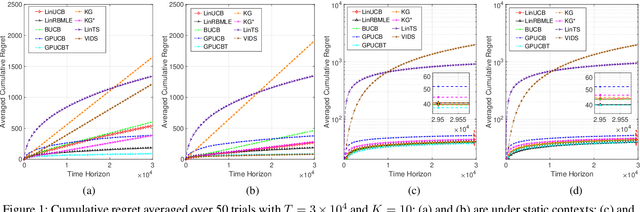
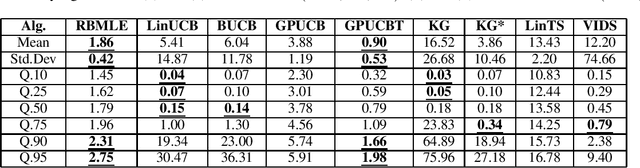
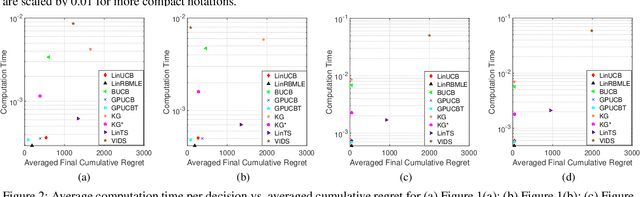

Modifying the reward-biased maximum likelihood method originally proposed in the adaptive control literature, we propose novel learning algorithms to handle the explore-exploit trade-off in linear bandits problems as well as generalized linear bandits problems. We develop novel index policies that we prove achieve order-optimality, and show that they achieve empirical performance competitive with the state-of-the-art benchmark methods in extensive experiments. The new policies achieve this with low computation time per pull for linear bandits, and thereby resulting in both favorable regret as well as computational efficiency.
View paper on