 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Transducer: One Model Unifying Streaming and Non-streaming Speech Recognition
Paper and Code
Oct 07, 2020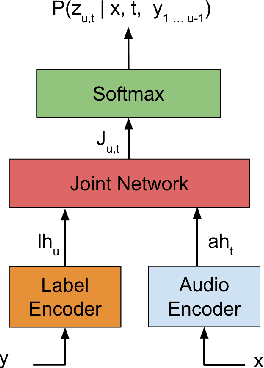
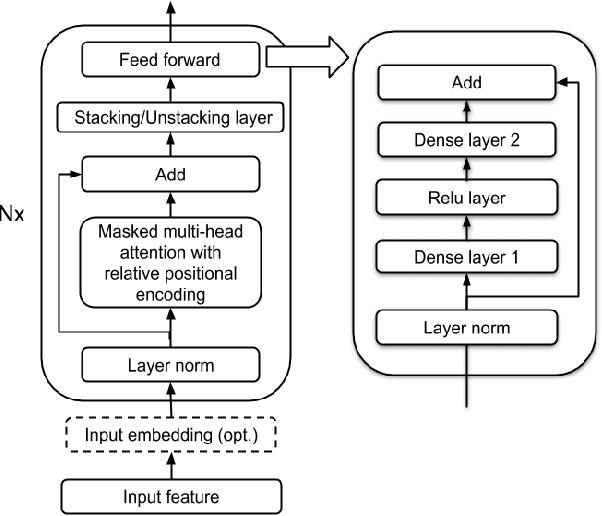
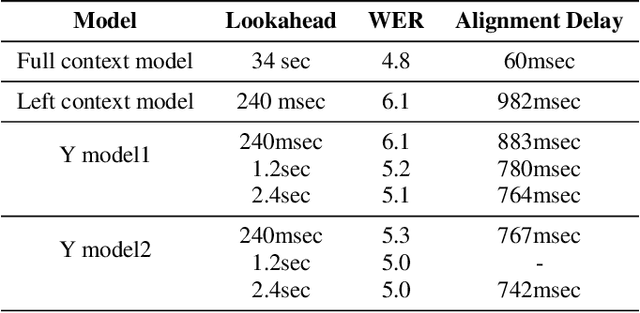
In this paper we present a Transformer-Transducer model architecture and a training technique to unify streaming and non-streaming speech recognition models into one model. The model is composed of a stack of transformer layers for audio encoding with no lookahead or right context and an additional stack of transformer layers on top trained with variable right context. In inference time, the context length for the variable context layers can be changed to trade off the latency and the accuracy of the model. We also show that we can run this model in a Y-model architecture with the top layers running in parallel in low latency and high latency modes. This allows us to have streaming speech recognition results with limited latency and delayed speech recognition results with large improvements in accuracy (20% relative improvement for voice-search task). We show that with limited right context (1-2 seconds of audio) and small additional latency (50-100 milliseconds) at the end of decoding, we can achieve similar accuracy with models using unlimited audio right context. We also present optimizations for audio and label encoders to speed up the inference in streaming and non-streaming speech decoding.