 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Classification By Few-Iteration Meta-Learning
Paper and Code
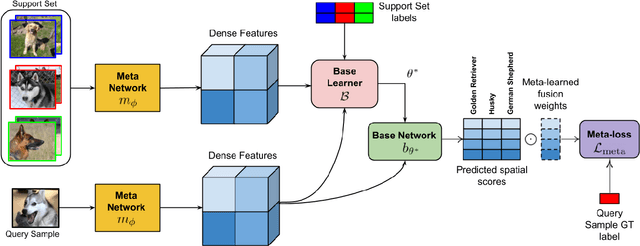
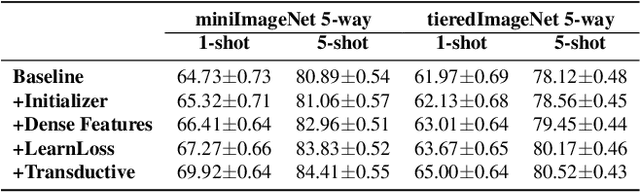

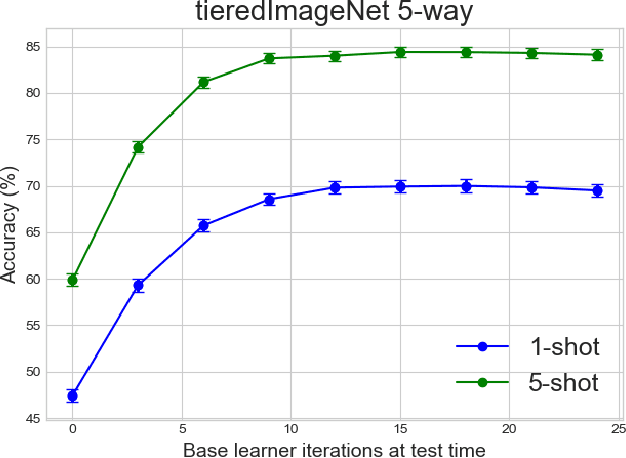
Learning in a low-data regime from only a few labeled examples is an important, but challenging problem. Recent advancements within meta-learning have demonstrated encouraging performance, in particular, for the task of few-shot classification. We propose a novel optimization-based meta-learning approach for few-shot classification. It consists of an embedding network, providing a general representation of the image, and a base learner module. The latter learns a linear classifier during the inference through an unrolled optimization procedure. We design an inner learning objective composed of (i) a robust classification loss on the support set and (ii) an entropy loss, allowing transductive learning from unlabeled query samples. By employing an efficient initialization module and a Steepest Descent based optimization algorithm, our base learner predicts a powerful classifier within only a few iterations. Further, our strategy enables important aspects of the base learner objective to be learned during meta-training. To the best of our knowledge, this work is the first to integrate both induction and transduction into the base learner in an optimization-based meta-learning framework. We perform a comprehensive experimental analysis, demonstrating the effectiveness of our approach on four few-shot classification datasets.