 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticVoxels: Sequential Fusion for 3D Pedestrian Detection using LiDAR Point Cloud and Semantic Segmentation
Paper and Code
Sep 25, 2020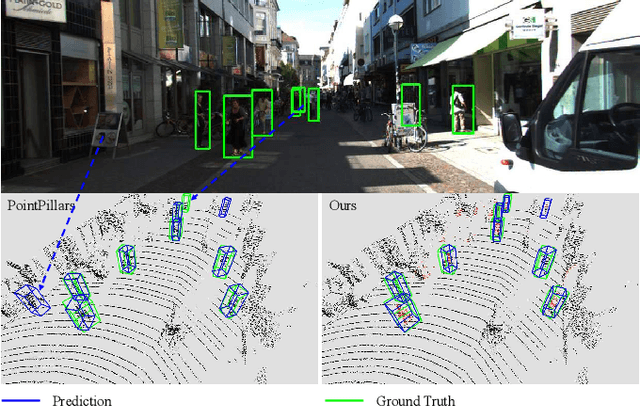
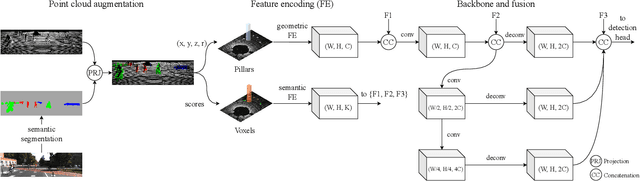

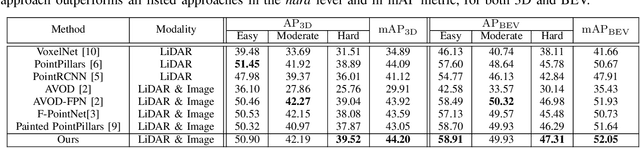
3D pedestrian detection is a challenging task in automated driving because pedestrians are relatively small, frequently occluded and easily confused with narrow vertical objects. LiDAR and camera are two commonly used sensor modalities for this task, which should provide complementary information. Unexpectedly, LiDAR-only detection methods tend to outperform multisensor fusion methods in public benchmarks. Recently, PointPainting has been presented to eliminate this performance drop by effectively fusing the output of a semantic segmentation network instead of the raw image information. In this paper, we propose a generalization of PointPainting to be able to apply fusion at different levels. After the semantic augmentation of the point cloud, we encode raw point data in pillars to get geometric features and semantic point data in voxels to get semantic features and fuse them in an effective way. Experimental results on the KITTI test set show that SemanticVoxels achieves state-of-the-art performance in both 3D and bird's eye view pedestrian detection benchmarks. In particular, our approach demonstrates its strength in detecting challenging pedestrian cases and outperforms current state-of-the-art approaches.